

Po uważnym przeczytaniu poprzednich rozdziałów i wykonaniu zawartych w nich ćwiczeń wiesz już, czym są i do czego służą języki HTML i CSS, orientujesz się, czym są elementy HTML, masz na swoim komputerze programy potrzebne Ci do pracy oraz wiesz, jak się nimi posługiwać w podstawowym zakresie.
W tym rozdziale dokładnie poznasz podstawową strukturę dokumentu HTML, z którą pobieżnie mieliśmy już okazję się zapoznać np. przy omawianiu wtyczki Emmet do Visual Studio Code. Dodatkowo stworzysz bazę do rozbudowy, na której będziesz później pracować.
Przykładowa strona
Poniższy zrzut ekranu przedstawia stronę internetową, którą utworzymy w tym rozdziale. Dzięki uważnemu zapoznaniu się z treścią poprzednich rozdziałów stworzenie takiej strony nie sprawi Ci praktycznie żadnego problemu. Wiesz już prawie wszystko, co trzeba. Musisz tylko poznać parę nowych elementów HTML.
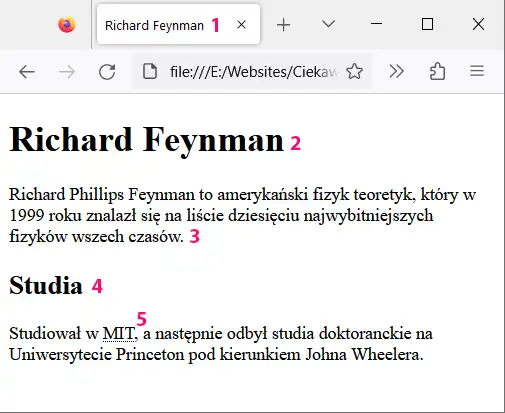
Tak będzie wyglądała Twoja pierwsza strona HTML. Poszczególne części zostały ponumerowane, aby łatwiej było się do nich odnosić.
Niektóre elementy HTML potrzebne do budowy tej strony wpadły Ci już w oko w poprzednich rozdziałach, więc nie są dla Ciebie całkowitą nowością. Na przykład wiesz już, że akapity tworzymy za pomocą elementu p.
Kod źródłowy
Pora przyjrzeć się naszej stronie „od wewnątrz”. Poniżej znajduje się jej kod źródłowy. Przyjrzyj się mu uważnie. Cyfry w nawiasach nie należą do kodu, tylko ułatwiają powiązanie kodu z tym, co widać na wcześniejszym zrzucie ekranu. Następnie przeczytaj dalsze objaśnienia poszczególnych elementów.
<!DOCTYPE html>
<html lang="pl">
<head>
<meta charset="utf-8">
<title>Richard Feynman</title> (1)
</head>
<body>
<h1>Richard Feynman</h1> (2)
<p>Richard Phillips Feynman to amerykański fizyk teoretyk, który w 1999 roku znalazł się na liście dziesięciu najwybitniejszych fizyków wszech czasów.</p> (3)
<!-- Przydałoby się zdjęcie -->
<h2>Studia</h2> (4)
<p>Studiował w <abbr title="Massachusetts Institute of Technology">MIT</abbr> (5), a następnie odbył studia doktoranckie na Uniwersytecie Princeton pod kierunkiem Johna Wheelera.</p>
</body>
</html>Struktura dokumentu
Każdy dokument HTML (dokument HTML to bardziej formalne określenie oznaczające po prostu stronę internetową albo plik HTML) ma określoną strukturę ramową, tzn. zawiera pewne podstawowe elementy, których stosowanie jest obowiązkowe. Są one przeznaczone głównie dla przeglądarki internetowej, ponieważ określają różne techniczne aspekty strony, np. w jakiej wersji języka HTML jest utworzona, w jakim języku naturalnym jest jej treść itp. Niektóre służą też użytkownikowi, np. element title zawiera tytuł strony, który jest widoczny na karcie w oknie przeglądarki. Przyjrzymy się tym wszystkim elementom po kolei.

Deklaracja typu dokumentu
Pierwszym elementem dokumentu HTML jest tzw. deklaracja typu dokumentu (ang. document type declaration – DTD). Za jej pomocą określamy, ogłaszamy, w której wersji języka HTML jest napisany nasz dokument. W przeszłości istniało wiele wersji tego języka, dlatego w tym miejscu na starszych stronach można spotkać wiele różności. Gdybyśmy na przykład tworzyli stronę w języku XHTML 1.0, to użylibyśmy takiej deklaracji typu dokumentu:
<!DOCTYPE html
PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">Na szczęście najnowsza wersja języka HTML, której teraz się uczymy, to HTML5, a w niej deklarację typu dokumentu radykalnie uproszczono i teraz wystarczy napisać: <!DOCTYPE html>.
Element główny dokumentu
Cała zawartość strony znajduje się w elemencie głównym o nazwie html, czyli między znacznikami <html> i </html>. Jest on też nazywany korzeniem (ang. root), ponieważ strukturę strony internetowej często porównuje się do drzewa, którego korzeń stanowi właśnie ten element.
Ważnym, choć nie obowiązkowym, członem tego elementu jest atrybut lang, który określa, w jakim języku naturalnym jest napisana dana strona internetowa. W naszym przypadku jest to język polski, więc atrybutowi lang powinniśmy nadać wartość pl. Dlatego drugi element naszej strony ma właśnie postać <html lang="pl">.
Nagłówek dokumentu
Generalnie treść dokumentu można podzielić na dwie główne części – część nagłówkową i treść właściwą. Część nagłówkowa mieści się w elemencie head, a treść właściwa – w elemencie body (można obrazowo powiedzieć, że dokument HTML ma głowę i ciało).
W nagłówku umieszcza się różnego rodzaju informacje dotyczące samego dokumentu. Większość z nich nie jest przeznaczona dla użytkownika, tylko dla przeglądarek, robotów internetowych itd.
Nasz przykładowy dokument zawiera tylko dwa elementy, ponieważ tylko one są obowiązkowe:
<meta charset="utf-8">
<title>Richard Feynman</title>Pierwszy z powyższych elementów to tzw. element meta lub metaelement, który zawiera metadane. Metadane to informacje dotyczące samego dokumentu. W tym przypadku informacją tą jest to, że ten dokument wykorzystuje metodę kodowania znaków (charset to skrót od angielskich słów character set oznaczających zestaw znaków) o nazwie UTF-8. Metoda kodowania znaków to sposób, w jaki przeglądarka ma interpretować to, co wpisujemy. Szczegóły techniczne są dla nas nieistotne w tym przypadku. Wystarczy zapamiętać, że UTF-8 pozwala na stosowanie wszystkich znaków z alfabetu polskiego, a także wielu innych alfabetów z całego świata.
Element <meta charset="utf-8"> powinien być pierwszym elementem w nagłówku dokumentu.
Drugi element reprezentuje tytuł strony, który jest na przykład wyświetlany na karcie okna przeglądarki, czy używany na stronach wyników wyszukiwania przez wyszukiwarki internetowe. Jak na tytuł przystało, powinien zwięźle opisywać treść strony.
Te dwa elementy są obowiązkowe, ale to nie znaczy, że na nich należy poprzestać. Jest jeszcze kilka elementów metadanych i innych, które bardzo często spotyka się w nagłówku dokumentu. W szczególności już teraz warto poznać jeszcze dwa: link i script.
Element link służy do dołączania arkuszy stylów do strony internetowej. Wkrótce zaczniesz stopniowo poznawać technologię CSS i wtedy powiemy sobie znacznie więcej na temat zarówno elementu link, jak i innych metod dołączania arkuszy stylów do strony. Na razie spójrz tylko na przykładowy element link, który dołącza do strony arkusz stylów o nazwie style.css:
<link rel="stylesheet" href="style.css">Zwróć uwagę, że element link składa się tylko z jednego znacznika, tzn. nie ma znacznika zamykającego, jak na przykład </body>.
Element script z kolei służy do dodawania do strony skryptów JavaScript. Nie będziemy go używać w tym kursie, ponieważ nie zajmujemy się tu JavaScriptem, ale warto o nim wiedzieć, ponieważ występuje on na większości stron internetowych. Poniżej znajduje się przykład użycia elementu script w celu dołączenia do strony skryptu o nazwie skrypt.js.
<script src="skrypt.js"></script>Zwróć uwagę, że ten element ma zarówno znacznik otwierający, jak i zamykający. To znaczy, że za jego pomocą można nie tylko dołączyć skrypt znajdujący się w pliku zewnętrznym, ale też można wpisać skrypt bezpośrednio na stronie.
Treść główna dokumentu
Treść główna dokumentu mieści się między znacznikami <body> i </body> oraz obejmuje wszystko to, co widać w oknie przeglądarki jako zawartość strony. Prawie wszystko, co będziesz robić w tym kursie, będzie dotyczyć właśnie zawartości elementu body.
W naszym przykładzie w elemencie body użyliśmy czterech elementów – h1, h2, p i abbr. Element h1 reprezentuje nagłówek najwyższego poziomu, czyli zwykle główny tytuł strony, coś jak tytuł rozdziału. Element h2 to nagłówek drugiego poziomu, coś jak tytuł podrozdziału. Element p, reprezentuje akapit, a element abbr definiuje skrót.
Zatrzymamy się na chwilę przy elemencie abbr, który zawiera atrybut. Atrybuty to dodatkowe porcje informacji dotyczących elementów. Te informacje mogą być bardzo różne. Czasami jest to rozwinięcie skrótu, jak w przypadku atrybutu title elementu abbr, a czasami ścieżka do arkusza stylów, jak w przypadku atrybutu href elementu link. Zwróć uwagę na sposób definiowania atrybutów: należy wpisać nazwę atrybutu, znak równości i wartość w podwójnym cudzysłowie prostym, np. src="style.css". To najczęściej spotykany rodzaj atrybutu, ale są też inne. Niedługo je poznasz.
Komentarze HTML
Został nam do omówienia jeszcze jeden ważny element naszej strony: <!-- Przydałoby się zdjęcie -->. Jest to komentarz HTML, czyli tekst, który mimo że znajduje się w obrębie elementu body, nie jest wyświetlany przez przeglądarkę interpretującą kod HTML. Komentarz HTML jest narzędziem projektanta (albo programisty w przypadku języków programowania) do dodawania notatek. W tym przypadku na przykład dodaliśmy notatkę przypominającą, że przydałoby się umieścić na stronie jakieś zdjęcie Richarda Feynmana, aby uatrakcyjnić jej wygląd.
Komentarze w HTML definiuje się bardzo łatwo. Początek komentarza wyznacza ciąg znaków <!--, a koniec – -->. Można je umieścić w dowolnym miejscu kodu HTML poza wnętrzem znaczników, tzn. tak nie można: <p <!-- komentarz -->><p>Treść <!-- Komentarz --> akapitu.</p>. Spójrz też na poniższy przykład.
<p>To jest akapit</p>
<!-- To jest komentarz, którego nie będzie widać w oknie przeglądarki --><!-- To jest
bardzo długi
komentarz HTML.
-->
<p> To jest akapit, <!-- W tym akapicie jest komentarz --> a to dalsza treść akapitu.</p> Należy uważać, aby komentarz nie „wyłączał” znaczników w sposób uszkadzający strukturę dokumentu, jak poniżej.
<p> To jest <strong>interesujący <!-- </strong> --> akapit.</p>Wiesz już wszystko, co potrzeba, aby utworzyć bardzo prostą stronę HTML, która spełnia wszystkie wymagania poprawności.
A skąd wiadomo, czy po dodaniu różnych elementów strona nadal jest poprawna? Może któryś z elementów został użyty nieprawidłowo? Są na to dwa sposoby i oba trzeba stosować. Po pierwsze, należy po prostu dokładnie poznać język HTML i prawidłowo używać jego elementów. Po drugie należy korzystać ze specjalnych narzędzi do sprawdzania poprawności składni. Nazywają się one walidatorami.

Usuwanie błędów
Walidatory to narzędzia sprawdzające składnię kodu w dokumencie HTML. Jeśli na przykład zabraknie w nim któregoś elementu obowiązkowego albo któryś z nich umieścisz w niewłaściwym miejscu, ten program Cię o tym poinformuje.
Jeśli używasz edytora Visual Studio Code, to możesz zainstalować odpowiednie rozszerzenie. Warto skorzystać z tego rozwiązania ponieważ jest bardzo wygodne – informuje Cię o błędach na bieżąco, dzięki czemu od razu możesz je eliminować. Popularnym rozszerzeniem tego typu do Visual Studio Code jest HTMLHint.
Ewentualnie możesz skorzystać z zewnętrznego narzędzia, np. walidatora W3C. Zewnętrzny walidator jest mniej wygodny, ponieważ trzeba wyjść z edytora, aby wprowadzić plik lub wkleić kod do innego narzędzia.
HTMLHint
Visual Studio Code nie ma standardowo narzędzia do sprawdzania składni kodu HTML, ale istnieje wiele rozszerzeń, które dodają tę funkcjonalność. Jednym z nich jest HTMLHint. To świetne narzędzie, które na bieżąco informuje o znalezionych błędach w kodzie strony.
Aby zainstalować rozszerzenie HTMLHint w Visual Studio Code, uruchom edytor, kliknij ikonę rozszerzeń na pionowym pasku po lewej stronie i w polu wyszukiwania wpisz htmlhint.
Kliknij przycisk Zainstaluj wybranego narzędzia (wersja autorstwa Mike’a Kaufmana jest przestarzała i należy wybrać tę drugą). Po zakończeniu instalacji rozszerzenie od razu działa. Jeśli na stronie będą znajdować się jakiekolwiek błędy składniowe, na pasku stanu na dole będzie widoczna liczba wskazująca, ile ich jest. Należy ją kliknąć, aby wyświetlić szczegółowe informacje. Spójrz na poniższy zrzut ekranu.
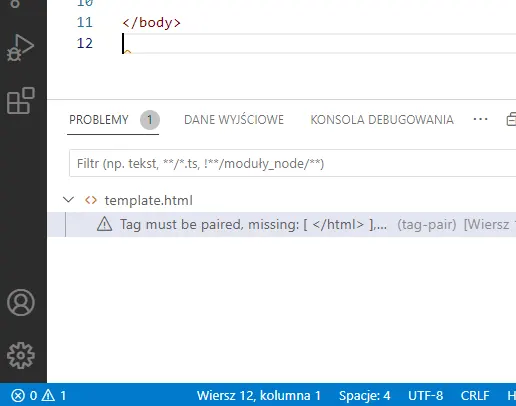
W tym przypadku na naszej stronie jest jeden błąd składni (cyfra 1 obok trójkąta z wykrzyknikiem po lewej stronie). Znajduje się on w 12 wierszu, w 1 kolumnie (Wiersz 12, kolumna 1). Błąd ten polega na tym, że zapomnieliśmy zamknąć element html, czyli nie wpisaliśmy na końcu dokumentu znacznika </html> – Tag must be paired, missing [ </html> ]….. Kiedy wpiszesz znacznik </html> w wierszu 12 tego pliku, błąd zniknie.
Walidator W3C
Walidator W3C znajduje się pod adresem https://validator.w3.org/. Ma bardzo prosty interfejs z trzema zakładkami: Validate by URI (Sprawdź przez podanie adresu), Validate by File Upload (Sprawdź przez przesłanie pliku) i Validate by Direct Input (Sprawdź przez bezpośrednie wprowadzenie kodu).
Kiedy wprowadzisz swój kod którąkolwiek z tych metod i klikniesz przycisk Check, narzędzie przeprowadzi analizę i wyświetli listę błędów i ostrzeżeń.
Znasz już podstawowe elementy budowy strony internetowej, wiesz czym są metadane, a nawet potrafisz definiować proste atrybuty elementów HTML. W następnym rozdziale nauczysz się dodawać obrazy graficzne do swoich stron, aby zwiększyć ich atrakcyjność.
Podsumowanie

Poniższa lista zawiera zwięzłe podsumowanie wiadomości opisanych w tym rozdziale:
<!DOCTYPE html>to definicja typu dokumentu. Każdy dokument powinien zawierać DTD. Ta definicja typu dokumentu oznacza, że jest to dokument HTML5.<html lang="pl">– element główny całego dokumentu. Fragment lang=”pl” to atrybut oznaczający, że jest to dokument w języku polskim. Zawsze należy określać język dokumentu w ten sposób, ponieważ m.in. ułatwia to pracę czytnikom ekranu, z których korzystają osoby z wadami wzroku.<head>– nagłówek dokumentu. W nagłówku przede wszystkim umieszcza się różne informacje dotyczące całej strony (tzw. metadane), określa się tytuł strony (widoczny między innymi na karcie w oknie przeglądarki) oraz dołącza się arkusze stylów i ewentualnie skrypty.<meta charset="utf-8">– określa metodę kodowania znaków na stronie: tu UTF-8. Powinien być pierwszym elementem nagłówka.<title>Tytuł</title>– tytuł strony.<link rel="stylesheet" href="style.css">– dołącza do strony arkusz stylów o nazwie style.css.<script src="skrypt.js"></script>– dołącza skrypt JavaScript o nazwie skrypt.js.<body>– treść właściwa strony, czyli wszystko, co będzie wyświetlane w oknie przeglądarki internetowej.<h1>...</h1>– element reprezentujący nagłówek pierwszego rzędu.<h2>...</h2>– element reprezentujący nagłówek drugiego rzędu.<p>...</p>– element reprezentujący akapit.<abbr>...</abbr>– element reprezentujący skrót.<!--...-->– komentarz, czyli element zawierający dodatkowe objaśnienia do kodu źródłowego, który jest ignorowany przez przeglądarki i nie jest wyświetlany na stronie.

Ćwiczenia
- Uruchom Visual Studio Code i w swoim folderze projektu utworzonym wcześniej utwórz nową stronę HTML o nazwie feynman.html.
- Przepisz do niej kod przykładowej strony z tego rozdziału. Znaczniki HTML przepisz, natomiast sam tekst możesz dla ułatwienia skopiować. Nie zapomnij usunąć numerów.
- Zainstaluj rozszerzenie HTMLHint i sprawdź poprawność składni swojego dokumentu.
- Jeśli Twój dokument nie zawiera żadnych błędów składni, usuń pierwszy
<h1>, aby dowiedzieć się, jak zareaguje program. - Przeczytaj powiadomienie o błędzie i napraw błąd.
- Otwórz swoją stronę w przeglądarce bezpośrednio z Visual Studio Code (skrót klawiszowy Ctrl+Shift+F9) i porównaj ją ze stroną pokazaną na zrzucie ekranu przedstawionym na początku tego rozdziału.

