
Dawno, dawno temu, przed powstaniem HTML5, w języku HTML istniały tzw. elementy prezentacyjne, czyli takie, których używało się wyłącznie w celu osiągnięcia określonego efektu wizualnego, np. element i kiedyś służył po prostu do wyświetlania tekstu pochylonego, a b do wyświetlania tekstu pogrubionego.

W HTML5 zmieniono podejście i całkowicie zrezygnowano z elementów prezentacyjnych. Od tej pory elementy HTML nie służą do nadawania tekstowi określonego wyglądu, tylko do nadawania mu określonego znaczenia, czyli wartości semantycznej. Do definiowania wyglądu, jak już doskonale wiemy, służą Kaskadowe arkusze stylów, czyli CSS.
Choć w HTML5 nie ma już elementów prezentacyjnych, część elementów, które miały taki charakter w HTML 4 i wcześniejszych wersjach, nadal są obecne w nowym standardzie. Teraz jednak mają inne zastosowanie. Na przykład element i, który kiedyś służył tylko do oznaczania tekstu pisanego kursywą (stąd też jego nazwa wywodząca się od angielskiego słowa italic), teraz służy do oznaczania fragmentów, które w jakiś sposób odstają od kontekstu, np. terminów technicznych, wyrażeń w obcym języku, jednostek taksonomicznych itd.
Z kolei elementy em i strong, choć nie były znacznikami prezentacyjnymi we wcześniejszych wersjach języka HTML, np. HTML 4, w HTML5 zostały lekko zmodyfikowane. Kiedyś oznaczały odpowiednio „emfazę” i „mocną emfazę”. Obecnie zaś element em oznacza emfazę (np. przeglądarki czytające treść stron na głos silniej zaakcentowałyby jego treść), a element strong reprezentuje ważny fragment tekstu.
Nie wszystkie elementy prezentacyjne z wcześniejszych wersji języka HTML zostały zachowane w HTML5 ze zmienionym znaczeniem. Całkowicie usunięto na przykład takie elementy, jak font, służący do definiowania właściwości tekstu, czy center, który wyrównywał tekst do środka.
To, że zawartość elementu i jest domyślnie prezentowana przez przeglądarki pismem pochyłym, jest sprawą drugorzędną. Ma to związek z tym, że w tradycyjnym druku tak właśnie oznacza się takie fragmenty tekstu. Nie znaczy to jednak, że nie można tego zmienić. Jeśli autor strony internetowej będzie miał takie życzenie, to za pomocą CSS może zmienić sposób prezentacji zawartości elementu i na czcionkę normalną albo pogrubioną, w dowolnym kolorze i rozmiarze.
W tym rozdziale poznasz elementy HTML5 używane do wyróżniania tekstu na różne sposoby (b, i, mark, em i strong) oraz poznasz kilka nowych własności CSS, które przydadzą Ci się do nadawania tym elementom indywidualnego wyglądu.
Dodatkowo poznasz bardzo uniwersalny element span, którego używa się wtedy, gdy chcemy w jakiś sposób wyróżnić tekst, a nie pasuje nam żaden z elementów semantycznych. Ten element tworzy nierozłączną parę z bardzo ważnym atrybutem o nazwie class, czyli dowiesz się także, czym są klasy w HTML oraz poznasz tzw. selektor klasy CSS – jeden z najczęściej używanych selektorów.
Zaczniemy od oznaczania ważnych fragmentów tekstu, czyli elementu strong, ale przedtem rzucimy okiem na bazowy dokument, na którym będziemy teraz pracować.

Baza HTML
Poniżej znajduje się kod źródłowy przykładowej strony o Richardzie Feynmanie, na bazie której będziemy pracować w tym rozdziale. Na razie jest pozbawiona elementów wyróżniania tekstu i dotyczących ich arkuszy stylów. Zawiera natomiast już arkusze stylów napisane we wcześniejszych rozdziałach.
<!DOCTYPE html>
<html lang="pl">
<head>
<meta charset="utf-8">
<title>Richard Feynman</title>
<style>
body {min-width: 600px; max-width: 800px; margin: 0 auto;}
h1, h2, h3 {margin-bottom: 0; margin-top: 30px;}
p {margin-top: 5px;}
blockquote {border-left: 6px solid green; padding: 10px 20px; margin-bottom: 0; text-align: justify;}
figcaption {margin-left: 66px; font-weight: bold; font-size: 90%;}
</style>
</head>
<body>
<h1>Richard Feynman</h1>
<p>Richard Phillips Feynman to amerykański fizyk teoretyk, który w 1999 roku znalazł się na liście dziesięciu najwybitniejszych fizyków wszech czasów.</p>
<img src="img/feynman.png" alt="Richard Feynman ze swoimi bębnami" width="300" height="241">
<h2>Studia</h2>
<p>Studiował w <abbr title="Massachusetts Institute of Technology">MIT</abbr>, a następnie odbył studia doktoranckie na Uniwersytecie Princeton pod kierunkiem Johna Wheelera, nie Stephena Hawkinga, jak niektórzy sądzą.</p>
<h2>Ciekawostki</h2>
<p>Feynman zajmował się wieloma dziedzinami fizyki, w tym kwantową teorią pola, fizyką cząstek elementarnych, czy kwantową teorią grawitacji. Kiedyś wyraził się na temat tych spraw w następujący sposób (zwróć uwagę na to, co mówił o świecie submikroskopowym):</p>
<figure>
<blockquote cite="https://www.brainyquote.com/authors/richard-p-feynman-quotes">
<p>„Przedmioty w bardzo małej skali zachowują się w sposób całkowicie odmienny od wszystkiego, co znamy. Nie przypominają fal, nie przypominają cząsteczek, nie przypominają chmur, kul bilardowych, ciężarków zawieszonych na sprężynach ani nie zachowują się jak cokolwiek, co kiedykolwiek widzieliśmy”.</p>
</blockquote>
<figcaption>— Richard Phillips Feynman</figcaption>
</figure>
<h3>Projekt Manhattan</h3>
<p>Feynman od bardzo młodych lat był uznawany za wybitnego fizyka, dzięki czemu otrzymał propozycję wzięcia udziału w projekcie Manhattan, którego celem było stworzenie bomby atomowej. Feynman uczestniczył w pierwszej próbie detonacji tej bomby w 1945 roku.</p>
<h3>Pochodzenie</h3>
<p>Richard Feynman wychował się w rodzinie żydowskiej oraz <b>miał korzenie rosyjskie i polskie</b> – ojciec jego matki, Lucille, wyemigrował z Polski. Ponadto jej matka także pochodziła z rodziny polskich imigrantów.</p>
<h3>Tuva or Bust</h3>
<p>Feynman fascynował się wchodzącą w skład Federacji Rosyjskiej republiką Tuwy, co wyrażał m.in. za pomocą hasła Tuva or Bust (Tuwa albo nic). W nawiązaniu do tej fascynacji jego przyjaciel, Ralph Leighton, napisał nawet książkę pod tym właśnie tytułem.</p>
</body>
</html>W przeglądarce ta strona wygląda teraz tak:

Ważne fragmenty tekstu
Do oznaczania ważnych fragmentów tekstu na stronie służy element strong (silny). Może to być jakaś ważna informacja, ostrzeżenie, przestroga albo fragment, który chcielibyśmy, aby został zauważony przez czytelnika jak najszybciej po wejściu na stronę.
W naszym przykładowym dokumencie możemy znaleźć wiele fragmentów tekstu, które kwalifikują się jako bardzo ważne informacje. Powiedzmy na przykład, że chcemy podkreślić wagę tego zdania: „Feynman uczestniczył w pierwszej próbie detonacji tej bomby w 1945 roku.”.
W tym celu umieszczamy je w elemencie strong, jak poniżej:
<p>Feynman od bardzo młodych lat był uznawany za wybitnego fizyka, dzięki czemu otrzymał propozycję wzięcia udziału w projekcie Manhattan, którego celem było stworzenie bomby atomowej. <strong>Feynman uczestniczył w pierwszej próbie detonacji tej bomby w 1945 roku.</strong></p>Standardowo zawartość elementu strong jest przez przeglądarki prezentowana pismem wytłuszczonym, więc nawet nie musimy nic zmieniać, aby nasza ważna informacja była wyróżniona. Teraz ten akapit w przeglądarce wygląda tak:

Już widać, że wybrany fragment tekstu jest ważny, ale możemy go uwypuklić jeszcze bardziej, np. przez zwiększenie rozmiaru czcionki za pomocą własności font-size. Własność ta przyjmuje jednostki długości, a także kilka słów kluczowych, w tym large, oznaczające czcionkę powiększoną. Użyjemy jej i sprawdzimy, jaki będzie efekt:
strong {font-size: large}Teraz wyróżniony tekst wygląda tak:
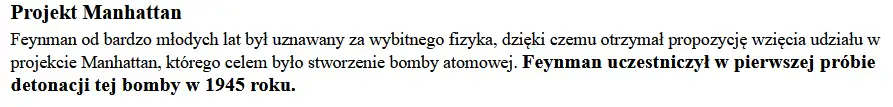
Ten tekst jest jeszcze bardziej wyróżniony. Możemy to tak zostawić i przejść do innego rodzaju wyróżnienia, które też tradycyjnie jest przedstawiane pismem wytłuszczonym – elementu b.
Zwracanie uwagi czytelnika

Jeśli chcemy wyróżnić fragment tekstu, ale nie chodzi nam o nadanie mu szczególnego znaczenia (np. podkreślenie jego wagi, jak w przypadku elementu strong), możemy użyć elementu b. Za jego pomocą możemy oznaczać słowa kluczowe, nazwy produktów w recenzjach, nazwy produktów w sklepie internetowym, pierwszy wiersz rozdziału itd.
Nazwa elementu b pochodzi od angielskiego słowa bold oznaczającego pogrubienie, ale obecnie ma ona tylko znaczenie historyczne, ponieważ ten element nie służy do pogrubiania, lecz do wyróżniania tekstu w dowolny sposób. Element b był elementem prezentacyjnym we wcześniejszych wersjach języka HTML, a w HTML5 nadano mu znaczenie semantyczne. Z tego powodu jest to jeden z tych elementów, których nazwa nie zgadza się z ich przeznaczeniem.
Standardowo przeglądarki wyświetlają zawartość elementu b pismem pogrubionym, więc gdybyśmy nie zdefiniowali żadnych arkuszy stylów, wizualnie byłby nie do odróżnienia od elementu strong.
W ramach przykładu powiedzmy, że chcemy zwrócić uwagę czytelnika na fakt, że Feynman miał korzenie polskie. Nie uznaliśmy tego za szczególnie ważną informację, więc nie używamy elementu strong, ale chcemy dopilnować, aby ta informacja nie umknęła uwadze czytelnika, więc umieścimy ją w elemencie b:
<p>Richard Feynman wychował się w rodzinie żydowskiej oraz <b>miał korzenie rosyjskie i polskie</b> – ojciec jego matki, Lucille, wyemigrował z Polski. Ponadto jej matka także pochodziła z rodziny polskich imigrantów.</p>Teraz ten i poprzedni akapit w przeglądarce wyglądają tak:

Dzięki temu, że zwiększyliśmy rozmiar czcionki elementu strong, odróżnia się on wizualnie od elementu b. Tyle nam wystarczy.
Teraz przejdziemy do szczególnego rodzaju wyróżnienia tekstu, ponieważ wiąże się ono ze sposobem wymawiania wyrazów – emfazy.

Emfaza
Kiedy czytamy tekst na głos, to stosujemy zróżnicowaną intonację w zależności od znaczenia poszczególnych fragmentów tekstu. Czasami podnosimy głos, czasami go ściszamy, a innym razem kładziemy większy nacisk (akcent) na wybrane słowa lub wyrażenia.
Do oznaczania właśnie takich fragmentów tekstu, które byśmy zaakcentowali podczas czytania tekstu na głos, służy element em (ang. emphasis – emfaza).
Na naszej przykładowej stronie mamy taki fragment tekstu: „odbył studia doktoranckie na Uniwersytecie Princeton pod kierunkiem Johna Wheelera, nie Stephena Hawkinga, jak niektórzy sądzą”. W tym przypadku możemy zaakcentować słowo „nie”, aby podkreślić, że Feynamn studiował pod kierunkiem jednego, a nie drugiego naukowca.
<p>Studiował w <abbr title="Massachusetts Institute of Technology">MIT</abbr>, a następnie odbył studia doktoranckie na Uniwersytecie Princeton pod kierunkiem Johna Wheelera, <em>nie</em> Stephena Hawkinga, jak niektórzy sądzą.</p>Standardowy sposób prezentacji zawartości elementu em przez przeglądarki to pismo pochyłe. Nasz przykład w oknie przeglądarki wygląda tak:

Jeśli chcemy dodatkowo wyróżnić ten tekst, możemy na przykład zwiększyć odstęp między literami, aby jeszcze wyraźniej odróżniał się od otoczenia. Odstęp między literami ustawiamy za pomocą własności CSS letter-spacing, która przyjmuje wartości wyrażone w jednostkach długości, np.:
em {letter-spacing: 0.15em;}Ta reguła ustawia odstęp między literami o wartości 0.15em, czyli 15/100 obecnego rozmiaru czcionki elementu. Uzależnienie tego ustawienia od rozmiaru czcionki jest bardzo dobrym pomysłem, ponieważ dzięki temu odstęp skaluje się wraz z rozmiarem tekstu. W przeglądarce wygląda to tak:

Teraz już nie da się przegapić naszej emfazy, możemy więc przejść do kolejnego elementu z kategorii wyróżniania tekstu, który standardowo daje taki sam efekt wizualny jak em. Jest to element i.
Odmienność od kontekstu
W wielu tekstach publikowanych na stronach internetowych można znaleźć pojęcia techniczne, wtrącenia w obcych językach, wyrażenia idiomatyczne, transliteracje obcych słów itp. fragmenty, które w pewnym sensie odróżniają się semantycznie od otaczającej treści charakterem, wydźwiękiem, brzmieniem itd.
Do oznaczania tego typu fragmentów treści służy element i. Jego nazwa, podobnie jak nazwa elementu b, jest myląca, ponieważ pochodzi od angielskiego słowa italic oznaczającego kursywę. Nie służy on jednak do prezentowania tekstu kursywą, tylko do celów opisanych powyżej. To zamieszanie wynika z zaszłości historycznych – jest to kolejny „stary” element prezentacyjny, który w HTML5 otrzymał nową definicję.
Na naszej stronie idealnym kandydatem do ujęcia w ten element jest wyrażenie Tuva or Bust z ostatniego akapitu:
<p>Feynman fascynował się wchodzącą w skład Federacji Rosyjskiej republiką Tuwy, co wyrażał m.in. za pomocą hasła <i lang="en">Tuva or Bust</i> (Tuwa albo nic). W nawiązaniu do tej fascynacji jego przyjaciel, Ralph Leighton, napisał nawet książkę pod tym właśnie tytułem.</p>Zwróć uwagę na dodatek atrybutu lang o wartości en. Oznacza on, że ten fragment tekstu jest napisany w języku angielskim. Dzięki prawidłowemu oznaczeniu różnych fragmentów tekstu za pomocą odpowiednio sformułowanego elementu i możemy stosować różne rodzaje formatowania przy użyciu CSS.
Na przykład w jednym z wcześniejszych akapitów znajduje się lista dziedzin fizyki, którymi zajmował się Feynman. Kwantowa teoria pola, fizyka cząstek elementarnych, czy kwantowa teoria grawitacji to pojęcia fizyczne, więc je też możemy umieścić w elemencie i.
Tekst w obcym języku i pojęcia fizyczne to całkiem odmienne rodzaje tekstu, więc przydałoby się je od siebie jakoś wizualnie odróżnić. W tym celu możemy wykorzystać tzw. selektor atrybutu, czyli selektor odnoszący się tylko do elementów mających określony atrybut.
Selektor atrybutu
W rozdziale poświęconym podstawom CSS została opisana najprostsza forma selektora atrybutu, która odnosi się do elementów mających określony atrybut. W naszym przypadku miałby on postać i[lang]. W wielu przypadkach to byłoby wystarczające – elementy i z atrybutem lang mają jeden rodzaj formatowania, a pozostałe elementy i (bez atrybutu lang) mają inny rodzaj formatowania.
Gdyby jednak na stronie mogły się trafić fragmenty tekstu w różnych językach, np. <i lang="fr">…</i>, i gdybyśmy chcieli je wizualnie rozróżniać, to potrzebowalibyśmy bardziej szczegółowego selektora atrybutu – odnoszącego się do jego wartości.
Selektor, o jaki nam chodzi, istnieje i jest bardzo prosty. Ma postać: [atrybut=wartość]. Na naszej stronie możemy go użyć w następujący sposób:
i[lang=en] {color: brown; font-style: normal}Dzięki powyższej regule tekst wszystkich elementów i w języku angielskim (mających atrybut lang o wartości en) na naszej stronie będzie brązowy i prosty. Pozostałe elementy i będą miały standardowe formatowanie dla tego elementu, czyli tylko pismo pochyłe w kolorze odziedziczonym po elemencie nadrzędnym. Spójrz na poniższy zrzut ekranu.

Pozostał nam jeszcze jeden element do wyróżniania tekstu – mark. Reprezentuje on tekst, który stał się istotny w pewnym kontekście. Poniżej dowiesz się, co to znaczy.

Cyfrowy zakreślacz
Element mark czasami porównuje się do zakreślacza lub markera, ponieważ ma podobne zastosowanie, tylko że na stronach internetowych, a nie na papierze.
Reprezentuje on tekst, który pierwotnie nie miał szczególnego znaczenia, ale stał się istotny w jakimś kontekście lub w związku z obecną aktywnością użytkownika. Używa się go więc na przykład do oznaczania znalezionych słów kluczowych na stronie albo do wyróżniania w cytatach blokowych fragmentów tekstu, na które chcemy zwrócić uwagę czytelnika.
Na naszej stronie mamy cytat blokowy, a przed nim nawet znajduje się akapit zawierający nawias, w którym zwracamy szczególną uwagę na fragment tego cytatu – „zwróć uwagę na to, co mówił o świecie submikroskopowym”. Oznaczymy więc teraz odpowiedni fragment tego cytatu za pomocą elementu mark.
<p>„<mark>Przedmioty w bardzo małej skali zachowują się w sposób całkowicie odmienny od wszystkiego, co znamy</mark>. Nie przypominają fal, nie przypominają cząsteczek, nie przypominają chmur, kul bilardowych, ciężarków zawieszonych na sprężynach ani nie zachowują się jak cokolwiek, co kiedykolwiek widzieliśmy”.</p>Standardowo zawartość elementu mark przeglądarki ozdabiają żółtym tłem, jak widać na poniższym zrzucie ekranu.

Kolor tła elementu mark możemy w łatwy sposób zmienić za pomocą własności CSS background-color, np.:
mark {background-color: pink;}Teraz element mark na naszej stronie będzie miał różowe tło:

Znamy już wszystkie elementy HTML5 do oznaczania różnego rodzaju wyróżnień. Czasami jednak zdarza się też tak, że chcemy w jakiś sposób wyróżnić fragment tekstu, ale nie pasuje nam on do żadnego z pięciu opisanych elementów semantycznych. W takim przypadku możemy posłużyć się elementem span z atrybutem klasy.
Inne wyróżnienia
Jeśli żaden z elementów semantycznych nie spełnia naszych wymagań, a chcemy wyróżnić jakiś fragment tekstu, to możemy użyć elementu span. Nie ma on wartości semantycznej i służy wyłącznie jako ogólny kontener pozwalający odnosić się do fragmentów tekstu, które w jakiś sposób chcemy sformatować.
Powiedzmy na przykład, że na naszej stronie chcemy wyróżnić nazwisko osoby, której ona dotyczy, czyli słowo Feynman. Do tego celu nie pasuje nam żaden z elementów semantycznych, więc użyjemy elementu span. Ponadto chcielibyśmy też jakoś wyróżniać nazwy uniwersytetów na stronie. Do tego też nie służy żaden konkretny element semantyczny, więc ponownie użyjemy elementu span.
Jeśli chcemy, aby nazwisko bohatera naszej strony i nazwy uniwersytetów były formatowane na różne sposoby, to mamy problem. Jeśli wszystkie te fragmenty tekstu oznaczymy elementem span, to reguła odnosząca się do tego elementu będzie im wszystkim nadawać takie same formatowanie. W takiej sytuacji z pomocą przychodzą klasy.
Klasy
W opisanej powyżej sytuacji możemy użyć klasy HTML. W języku tym istnieje globalny atrybut o nazwie class, za pomocą którego każdy element można przypisać do wybranej klasy (lub kilku klas – wówczas ich nazwy powinny być rozdzielone spacjami), aby móc się potem do niego odnieść w arkuszu CSS za pomocą specjalnego selektora.
Nazwa klasy może być dowolnym łańcuchem znaków spełniającym następujące warunki:
- Musi zaczynać się od małej lub wielkiej litery alfabetu łacińskiego.
- Może zawierać małe i wielkie litery, cyfry, łączniki oraz znaki podkreślenia.
W przypadku naszej strony możemy utworzyć dwie klasy: nazwisko i uniwersytet, które następnie możemy przypisać za pomocą atrybutu class do odpowiednich elementów span (lub dowolnych innych). Spójrz na poniższy kod.
<body>
<h1>Richard <span class="nazwisko">Feynman</span></h1>
<p>Richard Phillips <span class="nazwisko">Feynman</span> to amerykański fizyk teoretyk, który w 1999 roku znalazł się na liście dziesięciu najwybitniejszych fizyków wszech czasów.</p>
<img src="img/feynman.png" alt="Richard Feynman ze swoimi bębnami" width="300" height="241">
<h2>Studia</h2>
<p>Studiował w <span class="uniwersytet"><abbr title="Massachusetts Institute of Technology">MIT</abbr></span>, a następnie odbył studia doktoranckie na Uniwersytecie <span class="uniwersytet">Princeton</span> pod kierunkiem Johna Wheelera, <em>nie</em> Stephena Hawkinga, jak niektórzy sądzą.</p>
<h2>Ciekawostki</h2>
<p><span class="nazwisko">Feynman</span> zajmował się wieloma dziedzinami fizyki, w tym <i>kwantową teorią pola</i>, <i>fizyką cząstek elementarnych</i>, czy <i>kwantową teorią grawitacji</i>. Kiedyś wyraził się na temat tych spraw w następujący sposób (zwróć uwagę na to, co mówił o świecie submikroskopowym):</p>
<figure>
<blockquote cite="https://www.brainyquote.com/authors/richard-p-feynman-quotes">
<p>„<mark>Przedmioty w bardzo małej skali zachowują się w sposób całkowicie odmienny od wszystkiego, co znamy</mark>. Nie przypominają fal, nie przypominają cząsteczek, nie przypominają chmur, kul bilardowych, ciężarków zawieszonych na sprężynach ani nie zachowują się jak cokolwiek, co kiedykolwiek widzieliśmy”.</p>
</blockquote>
<figcaption>— Richard Phillips <span class="nazwisko">Feynman</span></figcaption>
</figure>
<h3>Projekt Manhattan</h3>
<p><span class="nazwisko">Feynman</span> od bardzo młodych lat był uznawany za wybitnego fizyka, dzięki czemu otrzymał propozycję wzięcia udziału w projekcie Manhattan, którego celem było stworzenie bomby atomowej. <strong><span class="nazwisko">Feynman</span> uczestniczył w pierwszej próbie detonacji tej bomby w 1945 roku.</strong></p>
<h3>Pochodzenie</h3>
<p>Richard <span class="nazwisko">Feynman</span> wychował się w rodzinie żydowskiej oraz <b>miał korzenie rosyjskie i polskie</b> – ojciec jego matki, Lucille, wyemigrował z Polski. Ponadto jej matka także pochodziła z rodziny polskich imigrantów.</p>
<h3>Tuva or Bust</h3>
<p><span class="nazwisko">Feynman</span> fascynował się wchodzącą w skład Federacji Rosyjskiej republiką Tuwy, co wyrażał m.in. za pomocą hasła <i lang="en">Tuva or Bust</i> (Tuwa albo nic). W nawiązaniu do tej fascynacji jego przyjaciel, Ralph Leighton, napisał nawet książkę pod tym właśnie tytułem.</p>
</body>Gdybyśmy teraz wyświetlili tę stronę w przeglądarce, to w jej wyglądzie nic by się nie zmieniło w porównaniu z poprzednią wersją. Jest tak dlatego, ponieważ element span, jako że nie ma wartości semantycznej, nie ma też żadnego specjalnego formatowania domyślnego. Jeśli chcemy wyróżnić go wyglądem, musimy użyć arkuszy stylów.
Powiedzmy że nazwisko naszego bohatera chcemy wyróżniać kolorem ciemnozielonym i lekkim „rozstrzeleniem liter”, a nazwy uniwersytetów chcemy oznaczyć kolorem bordowym. W tym celu musimy napisać dwie reguły CSS, po jednej z selektorem atrybutu class o odpowiedniej wartości:
span[class=nazwisko] {color: darkgreen; letter-spacing: 0.1em}
span[class=uniwersytet] {color: darkred}Ten kod jest prawidłowy i działa, ale klasy są tak często używane, że w CSS utworzono specjalny selektor umożliwiający odnoszenie się do nich za pomocą krótszej składni. Ma on postać kropki, po której należy wpisać nazwę klasy, np.
span.nazwisko {color: darkgreen; letter-spacing: 0.1em}
span.uniwersytet {color: darkred}Ponadto klasy często stosuje się do różnych elementów. Powiedzmy na przykład, że chcemy aby wybrane elementy span, abbr i strong miały kolor zielony. W takim przypadku każdemu interesującemu nas elementowi przypisujemy odpowiednią klasę, np. zielony:
<span class="zielony">…</span>
<abbr class="zielony">…</abbr>
<strong class="zielony">…</strong>Następnie w arkuszu stylów dodajemy regułę odnoszącą się do samej klasy, bez określenia konkretnego elementu, np.:
.zielony {color: green}Od tej pory wszystkie elementy przypisane do klasy zielony będą miały zielony kolor tekstu.
Wracając do naszej strony, ostatecznie potrzebne nam reguły CSS mogą wyglądać tak:
.nazwisko {color: darkgreen; letter-spacing: 0.1em}
.uniwersytet {color: darkred}Dodaj te reguły do arkusza stylów na swojej stronie, która teraz powinna wyglądać tak:

Poniżej dla przypomnienia jest pokazany kompletny arkusz stylów użyty na tej stronie:
<style>
body {min-width: 600px; max-width: 800px; margin: 0 auto; padding: 10px}
h1, h2, h3 {margin-bottom: 0; margin-top: 30px;}
p {margin-top: 5px;}
blockquote {border-left: 6px solid green; padding: 10px 20px; margin-bottom: 0; text-align: justify;}
figcaption {margin-left: 66px; font-weight: bold; font-size: 90%;}
strong {font-size:large;}
em {letter-spacing: 0.15em;}
i[lang=en] {color: brown; font-style: normal;}
mark {background-color: pink;}
.nazwisko {color: darkgreen; letter-spacing: 0.1em}
.uniwersytet {color: darkred}
</style>Wiesz już całkiem sporo na temat semantyki tekstu i znasz niektóre najważniejsze własności CSS. W następnym rozdziale złapiemy oddech od tego tematu i nauczymy się tworzyć łącza do innych stron. A potem… Potem dokończymy kwestie semantyki tekstu.
Podsumowanie

- Do oznaczania ważnych fragmentów tekstu służy element
strong. - Własność CSS
font-sizeumożliwia ustawianie rozmiaru czcionki. - Aby zwrócić uwagę czytelnika na wybrany fragment tekstu, który nie jest bardzo ważny, należy użyć elementu
b. - Emfazę oznaczamy za pomocą elementu
em. - Własność CSS
letter-spacingumożliwia ustawienie odstępu między literami. - Do oznaczania fragmentów tekstu, które odbiegają tonem lub znaczeniem od kontekstu, służy element
i. - Selektor atrybutu może odnosić się m.in. do elementów mających określony atrybut lub mających określony atrybut o określonej wartości.
- Własność CSS
font-styleumożliwia zmianę stylu pisma na pochyłe lub proste. - Element
markpełni podobną rolę jak zakreślacz w rzeczywistym świecie. - Własność CSS
background-colorsłuży do określania koloru tła elementów. - Element
spanto ogólny kontener umożliwiający formatowanie wybranych fragmentów tekstu, którym nie chcemy nadać żadnej szczególnej wartości semantycznej. - Globalny atrybut
classumożliwia przypisywanie elementów HTML do klas. - Jeden element może być przypisany do kilku klas.
- W CSS istnieje specjalny selektor klasy w postaci kropki (
.), po której należy wpisać nazwę interesującej nas klasy.

Często mylone elementy
Czasami elementy opisane w tym rozdziale mylą się początkującym użytkownikom języka HTML. Dlatego w poniższej tabeli przedstawiono zwięzłe podsumowanie ich zastosowań z konkretnymi przykładami.
| Element | Zastosowanie | Przykłady |
|---|---|---|
| b | Zwrócenie uwagi czytelnika – nie nadaje oznaczonemu tekstowi większej wagi. Specyfikacja zaleca stosowanie go w ostateczności, tzn. kiedy nie pasuje żaden inny, bardziej konkretny, element (domyślnie pogrubienie) |
|
| em | Emfaza, zaakcentowanie – odpowiednik „zaakcentowania” w mowie (domyślnie kursywa) |
|
| i | Odmienność od kontekstu (domyślnie kursywa) |
|
| mark | Cyfrowy zakreślacz – tekst, który pierwotnie nie miał szczególnego znaczenia, ale stał się istotny w danym kontekście lub w związku z obecną aktywnością użytkownika. |
|
| strong | Ważny tekst (domyślnie pogrubienie) |
|


