

Znasz już podstawową strukturę dokumentu, więc wiesz mniej więcej, jak wygląda składnia HTML, np. tak wygląda podstawowy element HTML reprezentujący akapit:
<p>To jest akapit.</p>Elementy HTML przeważnie mają właśnie taką składnię, jak ten powyższy, tzn. składają się z 3 części: otwierający znacznik HTML, treść i zamykający znacznik HTML. Oprócz tego pod względem budowy można wyróżnić jeszcze tzw. elementy puste, czyli składające się tylko z jednego znacznika. Najpierw jednak zajmiemy się elementami parzystymi.

Elementy HTML parzyste
Elementy parzyste składają się ze znacznika otwierającego, treści i znacznika zamykającego. Spójrz na poniższy szczegółowy schemat.

Jak widać, składnia elementu HTML nie jest skomplikowana. Przeanalizujemy ją szczegółowo.
Znacznik otwierający (ang. start tag) składa się z otwierającego nawiasu trójkątnego (<), nazwy elementu (tu: p) i zamykającego nawiasu trójkątnego (>) – np. <p>.
Znacznik zamykający (ang. end tag) wygląda prawie tak samo, jak otwierający, tylko przed nazwą dodatkowo zawiera ukośnik /, który oznacza, że jest to właśnie znacznik zamykający – np. </p>.
To, co może być treścią elementu, zależy od jego typu. Na przykład element p może zawierać dowolny tekst i wiele innych elementów HTML, między innymi abbr, a, cite, em, strong – głównie służące do znakowania tekstu. W dalszych rozdziałach poznasz je wszystkie.
Omówiliśmy podstawową składnię elementu HTML, ale może pamiętasz z rozdziału poświęconego strukturze dokumentu HTML taki element: <abbr title="Massachusetts Institute of Technology">MIT</abbr>.
W tym przypadku znacznikiem otwierającym jest <abbr>, znacznikiem zamykającym jest </abbr>, a treścią jest MIT. Czym w takim razie jest fragment title="Massachusetts Institute of Technology"? To jest atrybut.
Atrybuty HTML przekazują dodatkowe informacje lub modyfikują zachowanie elementów. Definiuje się je w znaczniku otwierającym. Większość wymaga podania wartości, np. title, ale istnieje grupa tzw. atrybutów logicznych, które jej nie wymagają.
Definicja najczęściej spotykanego rodzaju atrybutu składa się z nazwy atrybutu, znaku równości i wartości. Wartość atrybutu może być ujęta w cudzysłów pojedynczy (') lub podwójny albo może nie być umieszczona w ogóle w cudzysłowie, ale tylko, jeśli nie zawiera spacji. W naszym przykładzie dopuszczalne są tylko dwie pierwsze wersje:
<abbr title="Massachusetts Institute of Technology">MIT</abbr>
<abbr title='Massachusetts Institute of Technology'>MIT</abbr>
Więcej na temat rodzajów atrybutów i sposobów ich definiowania dowiesz się w następnym rozdziale, który jest im poświęcony w całości.
Teraz zajmiemy się elementami pustymi.
Elementy HTML puste

Nazwa element pusty (ang. void element) może być odrobinę zwodnicza, ponieważ nasuwa myśl, że taki element nic nie dodaje na stronę. Prawda jest jednak inna. Elementy HTML puste po prostu nie mają znacznika zamykającego. Jest on niepotrzebny, ponieważ wszystkie informacje w ich przypadku są przekazywane w atrybutach.
Jeden element tego rodzaju już znasz. Jest to element meta, o którym była mowa w rozdziale Podstawowa struktura dokumentu HTML – <meta charset="utf-8">.
Poza tym, że mają tylko jeden znacznik, elementy puste pod względem składniowym niczym więcej nie różnią się od elementów parzystych. Też mogą zawierać atrybuty, które definiuje się w dokładnie taki sam sposób.
Elementów pustych jest o wiele mniej niż parzystych. Oprócz elementu meta należą do nich jeszcze m.in. elementy br, img i input, o których szerzej będzie mowa w dalszych rozdziałach.
Elementy HTML można klasyfikować także na kilka innych sposobów. Na przykład w HTML 4 elementy dzielono na blokowe (ang. block-level element) i śródliniowe (ang. inline element). To podział wg cech prezentacyjnych, dlatego w HTML5 zrezygnowano z tej klasyfikacji na rzecz innych sposobów kategoryzowania (zobacz Modele treści HTML5) i przeniesiono ją do CSS. Choć Kaskadowe arkusze stylów poznasz nieco później, to już teraz warto wiedzieć, czym elementy blokowe różnią się od śródliniowych.
Elementy blokowe i śródliniowe
Podział elementów na blokowe i śródliniowe bardzo ułatwia ich opisywanie, ponieważ odnosi się do ich ważnej cechy, która decyduje o sposobie zachowania na stronie wobec innych elementów.
Elementy blokowe
Elementy blokowe tworzą na stronie odrębny blok treści, a w najprostszym ujęciu można powiedzieć, że powodują wstawienie złamania wiersza i zajmują całą dostępną szerokość okna przeglądarki – rozciągają się od lewej do prawej krawędzi tak, że nic już obok nich nie umieścimy, oczywiście jeśli nie zastosujemy reguł CSS, które to zmieniają.
Przykładem elementu blokowego jest p (akapit). Gdybyśmy na naszej stronie umieścili trzy akapity obok siebie, to w oknie przeglądarki zostałyby one wyświetlone jeden pod drugim. Spójrz na poniższy zrzut ekranu:

Kod źródłowy tego przykładu wygląda tak (dla uproszczenia pokazany jest tylko kod akapitów, bez szablonowych elementów head, body itd.).
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.</p>
<p>Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit.</p>
<p>In voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.</p>Jak widać, każdy akapit tworzy odrębny blok treści. Gdybyśmy nie użyli elementów p, to cały tekst tworzyłby jeden ciąg znaków, nawet gdybyśmy w edytorze wpisali go w poniższy sposób:
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit.
In voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. Mimo że w edytorze podzieliliśmy nasz tekst na akapity, to przeglądarka potraktuje je wszystkie jako jeden ciąg tekstu. Spójrz na poniższy zrzut ekranu.

Aby jeszcze lepiej uwidocznić granice między akapitami, możemy zdefiniować im obramowanie za pomocą CSS (wkrótce też nauczysz się to robić). Poniższy zrzut ekranu przedstawia nasz wcześniejszy przykład z włączonym obramowaniem elementów p.

Na tej ilustracji ukazano krawędzie okna przeglądarki, aby można było zobaczyć, że akapity zajmują całą dostępną przestrzeń w poziomie oraz tyle, ile im potrzeba miejsca w pionie. Za odstęp między lewą i prawą krawędzią tych elementów, a krawędzią okna przeglądarki odpowiada margines standardowo stosowany przez przeglądarkę do elementu body, w którym, jak może pamiętasz, mieści się cała treść właściwa strony.
Elementy śródliniowe
Elementy śródliniowe, w odróżnieniu od blokowych, nie powodują utworzenia nowego bloku treści na stronie ani złamania wiersza. Jak ich nazwa wskazuje, pozostają one w linii i zachowują się tak samo, jak zwykły tekst.
Przykładem elementu śródliniowego jest znany nam już z wcześniejszych rozdziałów element abbr reprezentujący skrót. To logiczne, że nie tworzy on osobnego bloku, ponieważ skróty są elementem tekstu i nie chcielibyśmy, aby każdy zajmował osobny wiersz lub w jakikolwiek inny sposób zaburzał strukturę wiersza tekstu.
Poniżej znajduje się przykład użycia elementu śródliniowego abbr w elemencie blokowym p zaczerpnięty z rozdziału o strukturze dokumentu HTML5.
<p>Studiował w <abbr title="Massachusetts Institute of Technology">MIT</abbr>, a następnie odbył studia doktoranckie na Uniwersytecie Princeton pod kierunkiem Johna Wheelera.</p>W przeglądarce wygląda to tak:
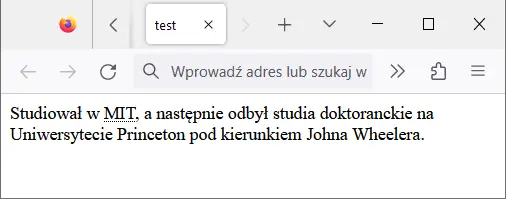
Jak widzisz, skrót MIT nie został umieszczony w osobnym bloku, tylko zajmuje normalne miejsce wśród innych wyrazów.
Generalnie można powiedzieć, że elementy blokowe służą do definiowania struktury treści lub dokumentu, a elementy śródliniowe w większości służą do oznaczania różnego rodzaju cech tekstu. Za ich pomocą możemy na przykład poinformować przeglądarkę, że dany fragment jest skrótem o określonym rozwinięciu albo że wybrany wyraz jest bardzo ważny lub stanowi fragment kodu komputerowego.
W dalszych rozdziałach poznasz szczegółowo wszystkie elementy śródliniowe języka HTML5. Na razie jednak interesują nas bardziej „techniczne” kwestie związane z elementami i znacznikami.
Wiesz już, że jedne elementy HTML można umieszczać w innych. Czynność ta nazywa się zagnieżdżaniem. Zgłębimy ten temat dokładniej, ponieważ wiedza ta będzie nam potrzebna do sprawnego posługiwania się językiem CSS (a konkretnie tzw. selektorami), a także jest niezbędna do pisania skryptów na strony internetowe w języku JavaScript.
Przedtem jednak zapoznasz się z pojęciem drzewa dokumentu.
Drzewo dokumentu HTML

Elementy HTML na stronie tworzą rodzaj struktury hierarchicznej zwanej drzewem dokumentu, która przypomina drzewo genealogiczne. Korzeniem (ang. root) tego drzewa, czyli jego elementem głównym, jest element html. Od niego wywodzą się wszystkie pozostałe elementy na stronie. Zatem element html jest ich rodzicem (ang. parent), a one są jego dziećmi (ang. child).
Na prawdziwym drzewie genealogicznym osoby łączą różne rodzaje pokrewieństwa. Na przykład, jedna osoba może mieć zarówno prawnuki, wnuki i dzieci oraz rodziców, dziadków i pradziadków i dalszych przodków.
Podobnie jest z elementami w drzewie dokumentu HTML. Jeden element może być dzieckiem lub dalszym potomkiem, jak również rodzicem lub dalszym przodkiem innego elementu. Spójrz na poniższy przykładowy dokument HTML.
<!DOCTYPE html>
<html lang="pl">
<head>
<meta charset="UTF-8">
<title>Dokument</title>
</head>
<body>
<p>Bardzo ciekawy i wciągający tekst.</p>
<p>Drugi ciekawy akapit.</p>
</body>
</html>Drzewo tego dokumentu wygląda tak:

Przeanalizujemy występujące na nim relacje hierarchiczne. Najpierw w relacji od przodka do potomka:
- Element
htmljest rodzicem (ang. parent) elementówheadibody(ponieważ zawiera je bezpośrednio) oraz przodkiem (ang. ancestor) elementówmeta,titleip(ponieważ zawiera je pośrednio przez elementyheadibody). - Element
headjest rodzicem elementówmetaititle. - Element
bodyjest rodzicem elementówp. - Ponadto elementy
metaititleoraz dwa elementypsą elementami siostrzanymi lub rodzeństwem (ang. siblings), ponieważ znajdują się na tym samym poziomie hierarchii względem siebie.
A teraz spojrzymy na hierarchię z odwrotnej strony, czyli od potomka do przodka:
- Każdy z elementów
pjest dzieckiem (ang. child) elementubody, ponieważ są w nim bezpośrednio zawarte. - Każdy z elementów
pjest potomkiem (ang. descendant) elementuhtml, ponieważ są w nim zawarte pośrednio przez elementbody. - Elementy
metaititlesą dziećmi elementuheadoraz potomkami elementuhtml.
Tak wyglądają relacje hierarchiczne między elementami w dokumencie. Nasze przykładowe drzewo jest bardzo proste, ale drzewo prawdziwej strony internetowej byłoby znacznie bardziej rozbudowane oraz miałoby bez porównania więcej gałęzi i poziomów zagnieżdżenia. A skoro mowa o zagnieżdżaniu, to już wiesz, na czym to polega, choć możesz nie wiedzieć, że tak to się nazywa. Najwyższa pora zapoznać się z tym pojęciem bardziej formalnie.
Zagnieżdżanie elementów HTML

Zagnieżdżanie elementów HTML oznacza po prostu umieszczanie jednych elementów w innych. Na przykład w naszym przykładowym dokumencie w elemencie html są zagnieżdżone elementy head, meta, title, body i p na różnych poziomach hierarchii. Czyli element html obejmuje te wszystkie elementy.
Zasady zagnieżdżania elementów są proste. Wystarczy pamiętać o jednej ważnej zasadzie: wszystkie zamykające znaczniki HTML muszą być wpisane w odwrotnej kolejności niż otwierające znaczniki HTML. To znaczy, że jeśli gdzieś w dokumencie otworzymy akapit za pomocą znacznika <p>, a w nim otworzymy skrót za pomocą znacznika <abbr>, to gdzieś dalej najpierw musimy umieścić znacznik zamykający skrótu </abbr>, a dopiero później znacznik zamykający akapitu </p>. Spójrz na poniższy przykład:
<p>Studiował w <abbr>MIT</abbr>.</p>W tym kodzie kolejność znaczników otwierających jest następująca: <p> > <abbr>. Natomiast kolejność znaczników zamykających wygląda tak: </abbr> > </p>. Ten kod jest prawidłowy pod względem składni HTML. Natomiast poniższy kod ma błędną składnię:
<p>Studiował w <abbr>MIT.</p></abbr>Tutaj popełniliśmy błąd składni i nie wiadomo, jak to zostanie potraktowane przez przeglądarkę internetową. Wprawdzie programy te „starają się” być pomocne i próbują odgadywać zamiary projektanta, ale lepiej nie liczyć na ich domyślność, tylko dbać o poprawność składni swoich dokumentów HTML.
Następny rozdział jest w całości poświęcony atrybutom elementów HTML. Zawiera trochę bardziej „technicznej” teorii, ale warto ją poznać przynajmniej pobieżnie, aby w przyszłości w pełni rozumieć przykłady kodu.
To będzie ostatni rozdział z części wprowadzającej. W kolejnym przechodzimy już do właściwej nauki posługiwania się różnymi elementami HTML i znakowania treści stron internetowych.
Podsumowanie

- Elementy HTML można podzielić na parzyste i puste.
- Elementy parzyste mają znacznik otwierający i zamykający.
- Element parzysty składa się ze znacznika otwierającego, treści i znacznika zamykającego.
- Elementy puste składają się tylko z jednego znacznika, tzn. nie mają znacznika zamykającego.
- Zasady definiowania atrybutów w elementach pustych są takie same, jak w elementach parzystych.
- Elementy HTML można podzielić także na blokowe i śródliniowe.
- Elementy blokowe zajmują całą dostępną szerokość w oknie przeglądarki i tworzą odrębne bloki.
- Elementy śródliniowe zachowują się jak zwykły tekst.
- Drzewo dokumentu HTML to hierarchiczna struktura przedstawiająca relacje pokrewieństwa między elementami HTML.
- Rodzic to element zawierający bezpośrednio inny element.
- Przodek to element zawierający pośrednio inny element.
- Dziecko to element będący bezpośrednim potomkiem innego elementu.
- Potomek to element będący pośrednim potomkiem innego elementu.
- Rodzeństwo lub elementy siostrzane to elementy występujące na tym samym poziomie drzewa dokumentu.
- Elementy HTML można zagnieżdżać wg ściśle określonych zasad.

Ćwiczenia
Narysuj, np. odręcznie na kartce lub dowolnym innym sposobem, drzewo poniższego dokumentu HTML i nazwij wszystkie elementy według ich miejsca w hierarchii, tzn. powiedz które elementy są rodzicami, potomkami, dziećmi itd. innych elementów.
<!DOCTYPE html> <html lang="pl"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <h1>To jest nagłówek dokumentu</h1> <p>To jest <abbr>np.</abbr> pierwszy akapit.</p> </body> </html>Popraw błędy składni HTML w poniższych fragmentach kodu. Najpierw zastanów się samodzielnie, a następnie skopiuj ten kod do Visual Studio Code i popraw błędy na podstawie wskazówek walidatora.
<abbr><p>Tekst</p></abbr> <p>Lorem ipsum dolor sit amet</h1> <P.>voluptate consequat nulla ullamco proident <abbr>EX aute ipsum sunt</p></abbr>

