

Większość stron internetowych opiera się głównie na treści tekstowej, która jest też najchętniej indeksowana przez wyszukiwarki internetowe. Kiedy czytamy książkę, gazetę lub jakikolwiek inny drukowany materiał, to praktycznie zawsze znajdziemy w nim przynajmniej dwa typowe elementy: nagłówki i akapity.
Nagłówki i akapity stanowią najbardziej podstawowy element treści tekstowej zarówno w mediach drukowanych, jak i elektronicznych. Ułatwiają jej uporządkowanie oraz pozwalają czytelnikowi szybko się zorientować, o czym traktuje dana sekcja dokumentu.
Przypomnijmy naszą pierwszą stronę o Richardzie Feynmanie, którą utworzyliśmy i przeanalizowaliśmy w rozdziale Struktura dokumentu HTML.
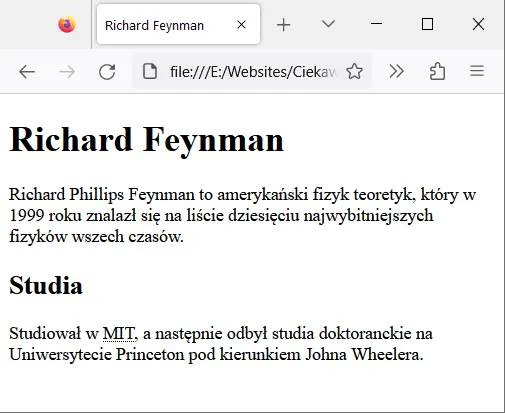
To bardzo prosty dokument zawierający tylko dwa nagłówki HTML („Richard Feynman” i „Studia”) i dwa akapity HTML („Richard Phillips…” i „Studiował w…”). Choć strona ta na razie nie wygląda imponująco, to zawiera dwa prawdopodobnie najczęściej używane elementy HTML: hx i p. Teraz w końcu przyjrzymy się im dokładnie.
Nagłówki HTML

Jak już wiesz, nagłówek to wyróżniony wizualnie napis umieszczony nad tekstem i stanowiący jego tytuł. Tak jak w książkach i gazetach, na stronach internetowych także można używać nagłówków różnego poziomu, np. tytuł rozdziału (strony), podrozdziału, punktu, podpunktu itd.
Do oznaczania nagłówków różnego rzędu służą elementy h1-h6, tzn. w języku HTML mamy do dyspozycji sześć poziomów nagłówka: h1, h2, h3, h4, h5 i h6. Pierwszy poziom (h1) oznacza nagłówek najwyższego rzędu, a więc najczęściej główny tytuł strony (rozdziału), drugi poziom (h2) oznacza nagłówek drugiego rzędu, a więc podtytuł strony (podrozdziału) itd.
Jeśli artykuł jest długi i zawiera kilka stopni podtytułów, należy zastosować nagłówki w odpowiedniej kolejności z zachowaniem hierarchii. To znaczy, główny tytuł strony zawsze oznaczymy elementem h1. Jeśli gdzieś dalej w treści zechcemy zdefiniować podtytuł, to powinniśmy użyć nagłówka h2, a nie h3 itd. Nagłówka h3 użyjemy dopiero wtedy, gdy zechcemy utworzyć podtytuł względem sekcji oznaczonej nagłówkiem h2.
Dokładnie takie same zasady mają zastosowanie w książkach, artykułach drukowanych i wszystkich innych tego typu publikacjach. Tytuł rozdziału w książce zostałby oznaczony nagłówkiem h1, a tytuł podrozdziału – nagłówkiem h2. Skład książki też nie zrobiłby przeskoku od rozmiaru odpowiadającego h1 od razu do rozmiaru odpowiadającego h3. A skoro o rozmiarach mowa…
Przeglądarki internetowe stosują domyślne ustawienia do wszystkich elementów HTML (które można zmienić za pomocą CSS). W przypadku nagłówków każdy kolejny poziom jest odrobinę mniejszy od poprzedniego, co pozwala je wizualnie od siebie odróżnić. Poniższy zrzut ekranu przedstawia domyślny wygląd wszystkich poziomów nagłówka po kolei w przeglądarce Firefox.

Wrócimy teraz do naszej strony o Richardzie Feynmanie. To niezwykle ciekawa i barwna osoba, która zasługuje na trochę obszerniejszą notkę biograficzną w naszym serwisie. Dodamy jeszcze dwa nagłówki, pod którymi za chwilę umieścimy parę kolejnych akapitów.
Dodawanie nagłówków do strony
Otwórz stronę feynman.html w wybranym przez siebie edytorze kodu (w tym kursie używamy Visual Studio Code). Dla przypomnienia poniżej jest pokazany jej kod źródłowy:
<!DOCTYPE html>
<html lang="pl">
<head>
<meta charset="utf-8">
<title>Richard Feynman</title>
</head>
<body>
<h1>Richard Feynman</h1>
<p>Richard Phillips Feynman to amerykański fizyk teoretyk, który w 1999 roku znalazł się na liście dziesięciu najwybitniejszych fizyków wszech czasów.</p>
<!-- Przydałoby się zdjęcie -->
<h2>Studia</h2>
<p>Studiował w <abbr title="Massachusetts Institute of Technology">MIT</abbr>, a następnie odbył studia doktoranckie na Uniwersytecie Princeton pod kierunkiem Johna Wheelera.</p>
</body>
</html>Jak widzisz, na tej stronie użyliśmy nagłówków h1 i h2. Pierwszy reprezentuje tytuł całej strony, a drugi – tytuł „podrozdziału”. Teraz dodamy parę kolejnych nagłówków, a potem pod nimi wprowadzimy kilka akapitów.
Kliknij za ostatnim zamykającym znacznikiem (tym przed słowem „Wheelera”) i naciśnij klawisz Enter, aby przejść do nowego wiersza. Wpisz następujące nagłówki:
<h2>Ciekawostki</h2>
<h3>Projekt Manhattan</h3>
<h3>Pochodzenie</h3>
<h3>Tuva or Bust</h3>Teraz w oknie przeglądarki strona powinna wyglądać tak:

Dodaliśmy parę nagłówków, ale brakuje nam jeszcze treści. Wprowadzimy ją teraz w formie akapitów.

Akapity HTML
Akapit to podstawowa jednostka logicznego podziału dłuższego tekstu na fragmenty w celu ich wizualnego wyróżnienia i zwiększenia czytelności. Do ich oznaczania w języku HTML służy element p (ang. paragraph). Jest to bardzo prosty element blokowy, który podobnie jak elementy nagłówka, składa się ze znacznika otwierającego (<p>), treści i znacznika zamykającego (</p>).
Poniżej znajdują się trzy akapity w takiej kolejności, w jakiej należy je wstawić pod nowymi nagłówkami trzeciego rzędu. Brakuje w nich znaczników, które musisz dodać samodzielnie. Dodaj do dokumentu w edytorze kodu odpowiednie elementy akapitów, a następnie skopiuj do nich fragmenty tekstu znajdujące się poniżej.
Teraz Twoja strona w oknie przeglądarki powinna wyglądać tak:

Jeśli teraz Twoja strona wygląda tak, jak na powyższym zrzucie ekranu, to znaczy, że wszystko powinno być w porządku. Może jednak pamiętasz z jednego z wcześniejszych rozdziałów, że przeglądarki „dużo wybaczają”, tzn. nawet kiedy popełnimy błąd składni, próbują odgadnąć nasze intencje i często im się udaje.
Dlatego teraz sprawdzisz, czy Twój dokument HTML ma prawidłową składnię. W tym celu otwórz w oknie edytora Visual Studio Code swoją stronę, jeśli jeszcze nie jest otwarta, i spójrz na lewą stronę paska stanu na dole okna. Po prawej stronie ikony trójkąta powinna znajdować się liczba 0. Każda inna wartość oznacza błędy, które trzeba naprawić. Spójrz na poniższą ilustrację:
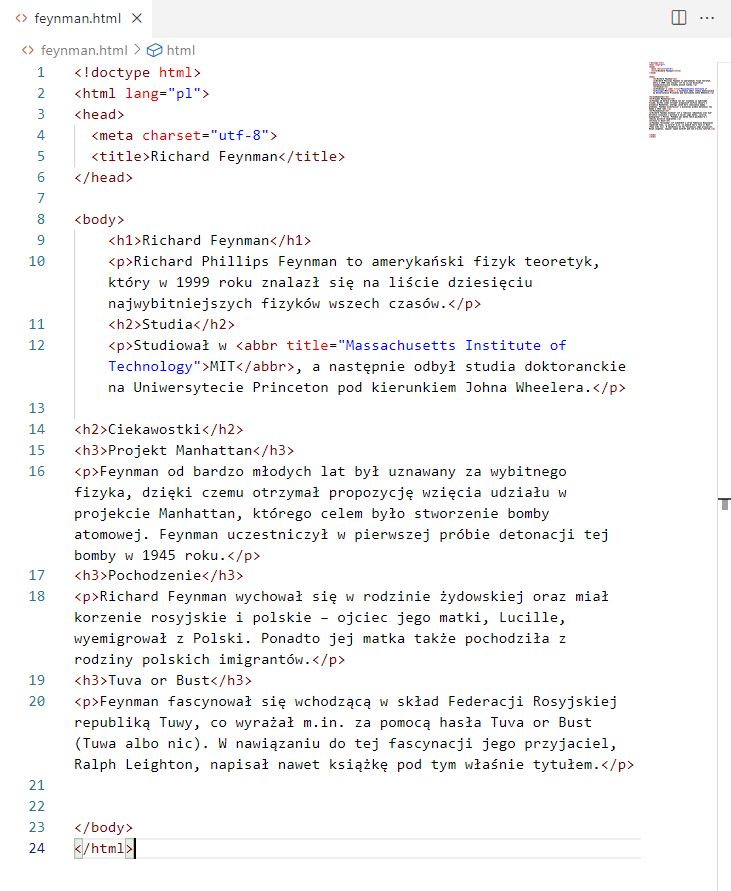
Teraz Twoja strona w edytorze może wyglądać mniej więcej tak. Składnia jest prawidłowa, wszystko ogólnie jest w porządku, a jednak można tu coś poprawić. Zwróć uwagę na znacznik <body> i znajdujący się bezpośrednio pod nim znacznik <h1>. Ten drugi jest przesunięty względem pierwszego. Nazywa się to wcięciem kodu.
Wcięcia kodu
Najczęściej stosowanym typem wcięcia kodu są cztery spacje, tzn. każdy kolejny poziom zagnieżdżenia elementów strukturalnych przesuwamy o cztery spacje względem poprzedniego. Tak zrobiono w przypadku elementów h1 i body na powyższej ilustracji.
Pamiętaj, że wcięcia stosuje się do elementów blokowych. Elementy śródliniowe traktujemy jak element tekstu akapitu, więc stosowanie do nich wcięć nie miałoby sensu.

Wcięcia kodu nie mają wpływu na sposób jego interpretacji przez przeglądarki, ale znacznie poprawiają jego czytelność. Dzięki nim od razu widzimy, które elementy są dziećmi, potomkami, rodzeństwem itd. innych elementów. Ponadto podczas wprowadzania zmian i ogólnie pracy nad stroną wcięcia ułatwiają uniknięcie wielu błędów, ponieważ pozwalają szybko zorientować się w ogólnej strukturze kodu.
Teraz spójrz na pierwszy element h2 i wszystko, co znajduje się pod nim. Tu już nie ma wcięć. Powodem jest wyłącznie niedbałość osoby, która pisała ten kod. Po prostu w trakcie pracy, zwłaszcza kiedy wkleja się fragmenty tekstu z innych edytorów, można zapomnieć o zastosowaniu wcięć. Czasami też zwyczajnie nie chce się ich robić, bo jesteśmy bardzo przejęci wykonywanym zadaniem.
Jeśli lubisz porządek w kodzie, to możesz robić wcięcia ręcznie w trakcie pisania kodu lub możesz je dodać później. To jednak bardzo żmudne i niewdzięczne zadanie. Na szczęście Visual Studio Code ma funkcję, która zrobi to błyskawicznie ze nas. Wystarczy w interesującym nas dokumencie otwartym w edytorze nacisnąć kombinację klawiszy Shift+Alt+F. W efekcie nasz kod w mgnieniu oka zostanie elegancko sformatowany. Poniżej widać efekt zastosowania tej funkcji do kodu z poprzedniej ilustracji.

Kiedy jest mowa o akapitach, to nie można zapomnieć o złamaniach wiersza. Tworzą je same elementy akapitu, ale czasami chcemy złamać wiersz wewnątrz akapitu, nie tworząc nowego, bo np. publikujemy poezję na naszej stronie… Teraz dowiesz się, jak to zrobić.
Złamania wiersza

W języku HTML są dostępne dwa elementy służące do łamania wierszy – br (ang. break – złamanie) i wbr (ang. word break – złamanie słowa). Pierwszy z nich łamie wiersz bezwarunkowo w miejscu, w którym się znajduje, a drugi pokazuje przeglądarce, gdzie można złamać wiersz, kiedy będzie taka potrzeba.
Złamanie bezwarunkowe (br)
Bezwarunkowe złamania wiersza stosuje się wszędzie tam, gdzie nie chcemy tworzyć nowych akapitów, ale chcemy przedstawić jakąś treść w formie obejmującej kilka wierszy. Jednym z typowych zastosowań elementu br jest więc na przykład publikowanie poezji, tekstów utworów muzycznych itd.
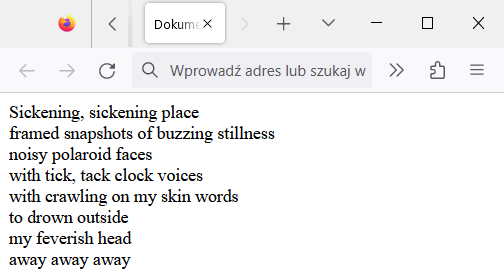
Gdyby Richard Feynman żył, to możliwe, że lubiłby muzykę zespołu Peccatum. Spójrz więc na poniższy przykład przedstawiający fragment tekstu utworu pt. Stillness tej grupy:
Sickening, sickening place<br>
framed snapshots of buzzing stillness<br>
noisy polaroid faces<br>
with tick, tack clock voices<br>
with crawling on my skin words<br>
to drown outside<br>
my feverish head<br>
away away away<br>W oknie przeglądarki wyglądałoby to tak, jak na poniższym zrzucie ekranu.
Złamanie warunkowe (wbr)
Bezwarunkowe złamanie wiersza stosujemy wtedy, gdy mamy bardzo długie słowo lub inny nieprzerwany fragment tekstu i chcemy mieć kontrolę nad tym, jak przeglądarka będzie go dzielić w zależności od szerokości okna. Ten rodzaj złamań stosuje się na przykład w ścieżkach do plików. Spójrz na poniższy przykład:
D:\Projekty<wbr>\Programy<wbr>\MójProgram<wbr>\Zasoby<wbr>\Pliki<wbr>\Podręcznik<wbr>\Nowe<wbr>\Folder<wbr>\KolejnyFolder<wbr>\JeszczeJedenFolder<wbr>\KoniecDługiejŚcieżki<wbr>\Plik.html
Znacznik <wbr> daje nam kontrolę nad wyglądem naszego tekstu bez względu na rozmiar okna przeglądarki.
Umiesz już tworzyć akapity i złamania wiersza, a nawet znasz fragment twórczości metalowego zespołu o nazwie Peccatum. Powoli przyzwyczajasz się też do widoku kodu źródłowego, który zaczyna być dla Ciebie coraz bardziej zrozumiały. Jeśli uważnie przyjrzysz się kodowi naszej strony o Richardzie Feynmanie, to Twoją uwagę może przyciągnąć jeden fragment – komentarz <!-- Przydałoby się zdjęcie -->.
Wstawiliśmy ten komentarz na stronę już na samym początku kursu, ale do tej pory się nim nie interesowaliśmy. Czas to zmienić. Zainteresujemy się nim w ten sposób, że go usuniemy, a w jego miejsce wstawimy zdjęcie bohatera naszej strony.
Podsumowanie

- W języku HTML są dostępne elementy do oznaczania sześciu poziomów nagłówków:
h1,h2,h3,h4,h5ih6. - Akapit to blok tekstu na stronie reprezentowany przez element blokowy
p. - Wcięcia kodu poprawiają jego czytelność i pomagają w unikaniu błędów składni.
- Element
brłamie wiersz bezwarunkowo w miejscu, w którym jest umieszczony. - Element
wbrłamie wiersz warunkowo w miejscu, w którym jest umieszczony. - Elementy
briwbrto elementy puste.

Ćwiczenia
- Utwórz nowy dokument HTML i zdefiniuj w nim po kolei nagłówki wszystkich poziomów.
- Pod każdym nagłówkiem dodaj akapit z tekstem „Lorem ipsum” wygenerowanym za pomocą rozszerzenia do Visual Studio Code zainstalowanego podczas studiowania rozdziału Składnia i rodzaje elementów HTML (ewentualnie użyj wskazanego tam generatora internetowego).
- Zaprowadź porządek w poniższym kodzie HTML (najpierw zrób to ręcznie w edytorze Visual Studio Code, a potem drugi raz, za pomocą odpowiedniej funkcji tego programu).
<!DOCTYPE html><html lang="pl"><head><meta charset="utf-8"><title>Richard Feynman</title></head><body><h1>Richard Feynman</h1><p>Richard Phillips Feynman to amerykański fizyk teoretyk, który w 1999 roku znalazł się na liście dziesięciu najwybitniejszych fizyków wszech czasów.</p><!-- Przydałoby się zdjęcie --><h2>Studia</h2><p>Studiował w <abbr title="Massachusetts Institute of Technology">MIT</abbr>, a następnie odbył studia doktoranckie na Uniwersytecie Princeton pod kierunkiem Johna Wheelera.</p></body></html>

