
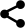
Wiemy już jak zmienić ścieżkę wykonywania programu za pomocą pętli i instrukcji rozgałęziających. Wcześniej dowiedzieliśmy się też czym są zmienne. Wszystkie te rzeczy można znaleźć w każdym języku programowania. Podobnie jest z funkcjami, o których będzie mowa w tym rozdziale.
Funkcje znajdują się we wszystkich programach w języku C++, także w tych, które oglądaliśmy do tej pory. Używa się ich po to, aby podzielić program na mniejsze moduły, jakby cegiełki używane do budowy programu. Tak jak z cegieł można zbudować dom, ogrodzenie domu albo garaż, za pomocą funkcji programista może zbudować różne programy. Zanim jednak przystąpimy do budowy jakichkolwiek konstrukcji, musimy najpierw narobić sobie cegieł. Później będziemy uczyć się murować przy ich użyciu.
7.1. Tworzenie i używanie funkcji
Funkcji używamy od samego początku tego kursu, zwłaszcza jednej, o nazwie main(). Stanowi ona punkt początkowy każdego programu w języku C++ i od niej zaczyna się jego wykonywanie.
#include <iostream>
using namespace std;
int main() // Początek funkcji main() i programu
{
cout << "Witaj, świecie!" << endl;
return 0;
} // Koniec funkcji main() i programu
Faktyczny początek tego programu znajduje się w wierszu 4., a koniec — w wierszu 8., za klamrą zamykającą. Zatem wszystko dzieje się wewnątrz jednej funkcji. Nie można wyjść poza nią. Instrukcje są wykonywane w takiej kolejności, w jakiej zostały wpisane.
Nasuwa się pytanie, czy istnieje możliwość tworzenia własnych funkcji, aby podzielić program na kilka niezależnych od siebie modułów? I czy to w ogóle miałoby sens?
Skoro cały kod można umieścić w funkcji main(), to po co dzielić go na jeszcze mniejsze kawałki? Wyobraź sobie, że chcesz napisać trójwymiarową grę komputerową. Jako że gry są bardzo skomplikowane, ich kod źródłowy składa się z setek tysięcy wierszy! Gdybyśmy cały ten kod umieścili w jednej funkcji, to bardzo trudno byłoby się w nim zorientować. O wiele prościej byłoby mieć osobny moduł kodu odpowiadający za ruchy postaci, inny odpowiadający za zmiany poziomów gry itd. Dzielenie programu na funkcje pozwala zapanować nad jego organizacją. Ponadto jeśli nad programem pracuje wielu programistów, łatwiej jest rozdzielić między nimi pracę. Każdy z nich może pracować nad przydzieloną mu funkcją.
Ale to nie wszystko! Weźmy na przykład obliczanie pierwiastka kwadratowego. Gdybyś pisał program matematyczny, to z pewnością obliczenia pierwiastka byłyby w nim wykonywane w różnych miejscach. Mając funkcję o nazwie sqrt() nie musisz wielokrotnie przepisywać tego samego kodu w wielu miejscach. Funkcji można używać wielokrotnie i to jest jeden z najważniejszych powodów, dla których się je tworzy.
7.1.1. Podstawy tworzenia funkcji
Funkcja to fragment kodu wykonujący ściśle określone zadanie. Podaje się jej dane, na których ma działać, a w zamian otrzymuje się wynik przetwarzania tych danych. Dane wejściowe funkcji nazywają się argumentami funkcji, natomiast to, co funkcja zwraca nazywa się wartością zwrotną funkcji (spójrz na poniższy rysunek).
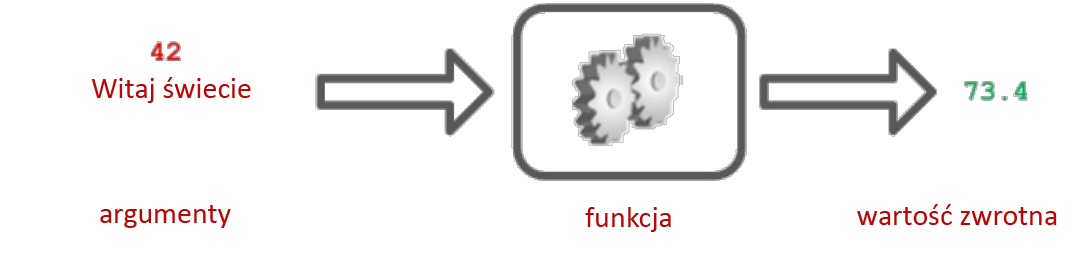
Pamiętasz funkcję potęgującą pow()? Posługując się poznaną przed chwilą terminologią, możemy sformułować następujące stwierdzenia na jej temat:
- Funkcja
pow()przyjmuje dwa argumenty. - Funkcja
pow()wykonuje obliczenia matematyczne. - Funkcja
pow()zwraca wynik obliczeń.
Działanie tej funkcji można przedstawić schematycznie w następujący sposób:
Jak wiesz, funkcji tej możemy używać w programie wielokrotnie. Dzięki temu nie musimy kopiować jej całego skomplikowanego kodu za każdym razem, gdy chcemy wykonać obliczenia.
7.1.2. Definiowanie funkcji
Czas na konkrety. W tym podrozdziale nauczymy się definiować własne funkcje. Mógłbym napisać żebyś przeanalizował budowę funkcji main() i samodzielnie do tego doszedł, ale jestem miły i pokażę Ci dokładnie, jak to się robi.
Ogólna budowa wszystkich funkcji jest taka sama:
type nazwaFunkcji(argumenty)
{
// Instrukcje wykonywane przez funkcję
}
Trzy składniki powyższego schematu już znasz. Jedyną nowością jest nazwa funkcji:
- Pierwszy składnik definicji funkcji to typ zwrotny. Określa on jakiego typu zmienną zwraca funkcja. Gdyby funkcja zwracała tekst, byłaby to zmienna typu
string, a gdyby zwracała wynik obliczeń, typem zwrotnym byłby np.intalbodouble. - Drugi składnik to nazwa funkcji. Znasz już m.in. funkcje o nazwach
main(),pow()isqrt(). Ważne jest aby nazwa funkcji odzwierciedlała jej przeznaczenie, podobnie jak jest w przypadku zmiennych. - W nawiasach znajduje się lista argumentów funkcji. Są to dane, na których funkcja będzie działać. Funkcja może przyjmować jeden argument (np.
sqrt()), więcej argumentów (np.pow()) albo nie przyjmować argumentów w ogóle. - Ostatnim składnikiem funkcji są klamry zawierające jej instrukcje. W klamrach tych znajdują się wszystkie instrukcje, które odpowiadają za działanie funkcji.
W następnym podrozdziale napiszemy przykładową funkcję.
7.1.3. Pierwsza funkcja
Na początek napiszemy bardzo prostą funkcję. Będzie ona przyjmowała liczbę całkowitą, dodawała do niej 2 i zwracała wynik:
int dodajDwa(int liczbaWejsciowa)
{
int wartosc(liczbaWejsciowa + 2); // Rezerwujemy miejsce w pamięci.
// Pobieramy wartość otrzymaną w argumencie i dodajemy do niej 2.
// Następnie zapisujemy wynik w pamięci.
return wartosc; // Wskazujemy, że wartością zwrotną funkcji jest wartość zmiennej wartosc
}
Przeanalizujemy szczegółowo kod tej funkcji. Tylko dwa wiersze zawierają nowy dla nas kod.
Pierwszego wiersza nie trzeba już objaśniać, ponieważ była mowa o tym wcześniej. Deklarujemy w nim funkcję o nazwie dodajDwa, która przyjmuje jako argument liczbę całkowitą i po zakończeniu działania zwraca również liczbę całkowitą.
Dalej znajduje się wiersz kodu, którego znaczenie również powinno być już dla Ciebie jasne. Jeśli masz problemy z jego zrozumieniem, polecam jeszcze raz przeczytać rozdział o używaniu pamięci.
Znajdująca się na samym końcu instrukcja return określa wartość zwrotną funkcji. W tym przypadku zwracana jest wartość zmiennej wartosc.
7.1.4. Wywoływanie funkcji
Zdefiniowaliśmy funkcję, ale nie wiemy jeszcze jak jej używać. Chwileczkę, przecież wcześniej posługiwaliśmy się już funkcjami. Przypomnij sobie funkcje matematyczne! Poniżej znajduje się przykład wywołania naszej nowej funkcji:
#include <iostream>
using namespace std;
int dodajDwa(int liczbaWejsciowa)
{
int wartosc(liczbaWejsciowa + 2);
return wartosc;
}
int main()
{
int a(2),b(2);
cout << "Wartość a: " << a << endl;
cout << "Wartość b: " << b << endl;
b = dodajDwa(a); // Wywołanie funkcji
cout << "Wartość a: " << a << endl;
cout << "Wartość b: " << b << endl;
return 0;
}
Do wywołania naszej funkcji użyliśmy znanej nam już notacji wynik = funkcja(argument). Prawda, że łatwe? Uruchom ten program, aby go wypróbować i dowiedzieć się, co zwróci.
W wywołaniu funkcji została zmodyfikowana wartość zmiennej b, a więc wszystko działa zgodnie z przewidywaniami.
7.1.5. Funkcje z kilkoma argumentami
Funkcja nie musi przyjmować tylko jednego argumentu. Istnieją przecież takie funkcje, jak pow() i getline(), które przyjmują ich więcej. Jeśli funkcja ma przyjmować więcej argumentów niż jeden, należy te argumenty wypisać jeden po drugim, rozdzielając je przecinkami:
int dodawanie(int a, int b)
{
return a+b;
}
double mnozenie(double a, double b, double c)
{
return a*b*c;
}
Pierwsza z powyższych funkcji sumuje przekazane jej argumenty, a druga oblicza ich iloczyn.
7.1.6. Funkcje nie przyjmujące argumentów
Możliwe jest także napisanie funkcji, która nie przyjmuje ani jednego argumentu. Należy po prostu nie wpisywać niczego w nawiasie.
Ale po co definiować takie funkcje? Mają one wiele zastosowań, np. funkcja pobierająca od użytkownika jego imię do działania nie potrzebuje żadnych parametrów.
string pobierzImie()
{
cout << "Wpisz swoje imię: ";
string imie;
cin >> imie;
return imie;
}
Myślę, że jak się zastanowisz, to bez trudu znajdziesz więcej tego typu przykładów. Mimo to rzeczywiście funkcje tego rodzaju są rzadkością.
7.1.7. Funkcje, które nic nie zwracają
Wszystkie funkcje, o których była do tej pory mowa pobierają jakieś argumenty i zwracają wartość. Ale można też utworzyć funkcję, która niczego nie zwraca. W tym celu jako typ zwrotny należy wpisać słowo kluczowe void oznaczające właśnie nic po angielsku. Gdy użyjemy tego słowa kluczowego, informujemy że nasza funkcja nie będzie niczego zwracać.
void przywitajSie()
{
cout << "Dzień dobry!" << endl;
// Ponieważ funkcja nic nie zwraca, nie ma instrukcji return!
}
int main()
{
przywitajSie(); // Ponieważ funkcja nic nie zwraca, wywołujemy ją
// bez przypisania wartości zwrotnej do zmiennej
return 0;
}
To wszystko na temat tworzenia funkcji, jeśli chodzi o teorię. W dalszej części rozdziału przedstawionych jest kilka przekładów definiowania i używania funkcji oraz zwięzłe podsumowanie wiadomości.
7.2. Przykłady funkcji
7.2.1. Podnoszenie do kwadratu
Zaczniemy od czegoś łatwego, czyli funkcji podnoszącej wartość do kwadratu. Będzie ona pobierała liczbę x i obliczała wartość x2.
#include <iostream>
using namespace std;
double kwadrat(double x)
{
double wynik;
wynik = x*x;
return wynik;
}
int main()
{
double liczba, wartoscPotegi;
cout << "Podaj liczbę: ";
cin >> liczba;
wartoscPotegi = kwadrat(liczba); // Użycie funkcji
cout << "Liczba " << liczba << " podniesiona do kwadratu wynosi " << wartoscPotegi << endl;
return 0;
}
Na początku podrozdziału obiecałem, że będzie zwięzłe podsumowanie wiadomości. Poniżej zatem przedstawiam schemat obrazujący kolejność wykonywania instrukcji powyższego programu.
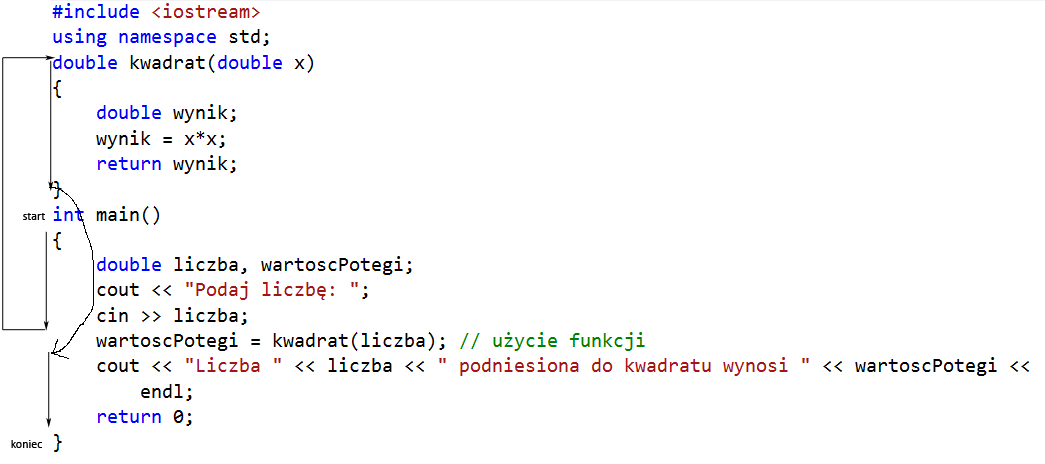
- Wykonywanie programu rozpoczyna się od początku funkcji
main(). - Następuje wykonanie trzech pierwszych wierszy kodu w normalny sposób.
- Program dochodzi do wywołania funkcji.
- Zostaje obliczona wartość argumentu funkcji, która jest równa wartości zmiennej
liczba. Zostaje ona skopiowana do zmiennejx. - Program przechodzi na początek funkcji
kwadrat()i wykonuje jej kod w normalny sposób. - Program dochodzi do końca funkcji
kwadrat(). Kopiuje wynik ze zmiennejwynikdo zmiennejwartoscPotegi. - Następuje powrót do funkcji
main()i kontynuacja wykonywania kolejnych wierszy kodu.
Jest jedna rzecz, o której należy koniecznie pamiętać. Wartości zmiennych przekazywanych do funkcji są kopiowane do nowych miejsc w pamięci. Oznacza to, że funkcja kwadrat() w istocie nie operuje na zmiennych zdefiniowanych w funkcji main(). Działa na swoich własnych kopiach tych zmiennych.
Dopiero instrukcja return powoduje zmodyfikowanie zmiennej z funkcji main() wartością zwrotną — w tym przypadku jest to zmienna o nazwie wartoscPotęgi. Wartość zmiennej liczba w wyniku wykonania funkcji pozostaje niezmieniona.
7.2.2. Wielokrotne wykorzystanie jednej funkcji
Funkcje definiuje się po to, aby w łatwy sposób móc wielokrotnie wykonywać te same czynności. W naszym przypadku możemy na przykład wyświetlić kwadraty wszystkich liczb całkowitych od 1 do 20:
#include <iostream>
using namespace std;
double kwadrat(double x)
{
double wynik;
wynik = x*x;
return wynik;
}
int main()
{
for(int i(1); i<=20 ; i++)
{
cout << "Liczba " << i << " podniesiona do kwadratu wynosi: " << kwadrat(i) <<
endl;
}
return 0;
}
Formułę obliczania kwadratu dowolnej liczby napisaliśmy tylko raz, a następnie użyliśmy jej 20 razy. Te obliczenia się bardzo proste, ale w realnych programach funkcje są o wiele dłuższe i bardziej skomplikowane, dzięki czemu oszczędza się dużo miejsca.
7.2.3. Funkcja z dwoma argumentami
Na zakończenie tego podrozdziału przedstawiam jeszcze jeden przykładowy program, tym razem zawierający funkcję przyjmującą dwa argumenty. Program ten będzie rysował prostokąt z gwiazdek w konsoli. Funkcja za to odpowiedzialna będzie przyjmować dwa argumenty: wysokość i szerokość prostokąta.
#include <iostream>
using namespace std;
void rysujProstokat(int l, int h)
{
for(int wiersz(0); wiersz < h; wiersz++)
{
for(int kolumna(0); kolumna < l; kolumna++)
{
cout << "*";
}
cout << endl;
}
}
int main()
{
int szerokosc, wysokosc;
cout << "Szerokość prostokąta: ";
cin >> szerokosc;
cout << "Wysokość prostokąta: ";
cin >> wysokosc;
rysujProstokat(szerokosc, wysokosc);
return 0;
}
Poniżej znajduje się przykładowy wynik działania tego programu.
Szerokość prostokąta: 16 Wysokość prostokąta: 3 **************** **************** ****************Oto początki powstawania programu, który zrewolucjonizuje rysowanie!
Funkcja rysujProstokat() wyświetla tylko tekst, a więc nie musi niczego zwracać. Dlatego jej typem zwrotnym jest void.
Możemy oczywiście w łatwy sposób ją zmodyfikować, aby np. zwracała pole powierzchni narysowanego prostokąta. W takim przypadku typ zwrotny musimy zmienić na int.
Poniżej przedstawiam dwa ćwiczenia do wykonania polegające na zmodyfikowaniu powyższej funkcji:
- Wyświetl informację o błędzie, jeśli użytkownik wpisze ujemną wartość dla szerokości lub wysokości.
- Dodaj argument pozwalający wybrać znak używany do rysowania.
Dobrej zabawy! Ważne jest, aby dokładnie zrozumieć wszystkie opisywane dotychczas zagadnienia.
Pozostała część tego rozdziału jest poświęcona trzem bardziej zaawansowanym zagadnieniom. Jeśli czegoś do końca nie zrozumiesz, będziesz mógł wrócić do tych opisów w przyszłości. Nie zapomnij też o wykonaniu ćwiczeń.
7.3. Przekazywanie argumentów przez wartość i przez referencję
Pierwszym z zaawansowanych zagadnień, o których chcę napisać jest sposób, w jaki komputer zarządza pamięcią podczas wywoływania funkcji.
7.3.1. Przekazywanie argumentów przez wartość
Weźmy na przykład prostą funkcję, której działanie polega na dodaniu 2 do argumentu. Poniżej przedstawiam jej kod:
int dodajDwa(int a)
{
a+=2;
return a;
}
Przetestujemy naszą funkcję. Poniżej znajduje się kompletny kod programu z jej użyciem:
#include <iostream>
using namespace std;
int dodajDwa(int a)
{
a+=2;
return a;
}
int main()
{
int liczba(4), wynik;
wynik = dodajDwa(liczba);
cout << "Oryginalna liczba: " << liczba << endl;
cout << "Wynik: " << wynik << endl;
return 0;
}
Wynik działania tego programu nie jest zaskakujący:
Oryginalna liczba: 4 Wynik: 6Najciekawsza część tego kodu znajduje się w wierszu 13. Pamiętasz jeszcze schematy pamięci? Przydadzą się nam jeszcze raz.
Po wywołaniu funkcji ma miejsce wiele wydarzeń:
- Program określa wartość zmiennej liczba, która wynosi
4. - Program alokuje fragment pamięci i zapisuje w nim wartość
4. Miejsce to ma nazwę a, ponieważ taka jest nazwa zmiennej w funkcji. - Program rozpoczyna wykonywanie funkcji.
- Program dodaje
2do zmiennej a. - Następuje skopiowanie wartości zmiennej a, która teraz wynosi
6, i przypisanie jej zmiennej wynik. - Program kończy wykonywanie funkcji.
Najważniejsze w tym wszystkim jest to, że wartość zmiennej liczba została skopiowana do nowego miejsca w pamięci. W takim przypadku mówi się, że zmienna a została przekazana przez wartość. Zatem w czasie gdy program wykonuje kod funkcji, zawartość pamięci wygląda tak, jak na poniższym rysunku.
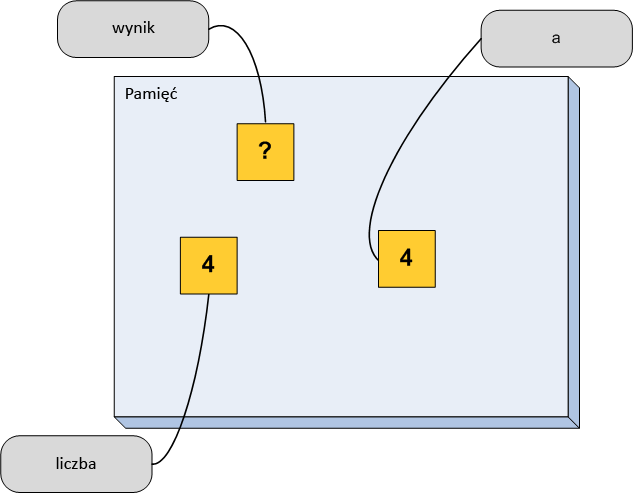
Mamy zatem zarezerwowane trzy miejsca w pamięci. Zwróć uwagę, że zmienna liczba pozostała niezmieniona.
Nie przez przypadek podkreślam, że wartość zmiennej liczba pozostaje niezmieniona.
7.3.2. Przekazywanie argumentów przez referencję
Pamiętasz co to są referencje? Była o nich mowa w jednym z wcześniejszych rozdziałów. W razie potrzeby przeczytaj go jeszcze raz, aby odświeżyć sobie pamięć. Teraz w końcu dowiesz się do czego referencje w ogóle mogą się przydać.
Zamiast kopiować wartość zmiennej liczba do zmiennej a, można zmiennej tej wewnątrz funkcji nadać drugą nazwę. Argumentem funkcji w takim przypadku musi być referencja.
int dodajDwa(int& a) // Zwróć uwagę na znak &!
{
a+=2;
return a;
}
Gdy wywołamy tę funkcję, program nie utworzy kopii zmiennej, tylko przekaże jej drugą nazwę. Spójrzmy jak to wygląda w pamięci:
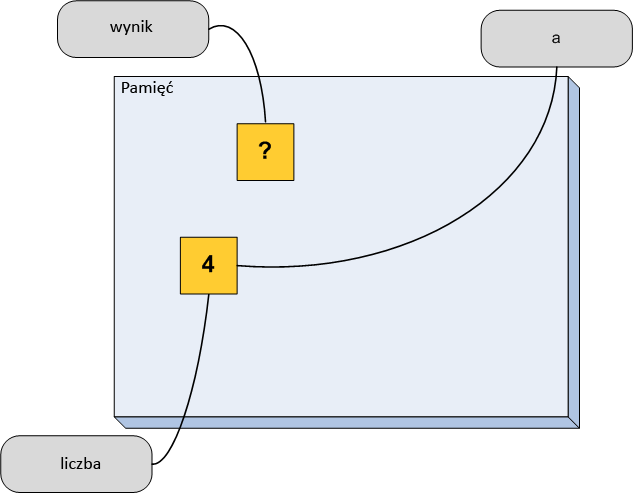
W tym przypadku nazwy a i liczba odnoszą się do tego samego miejsca w pamięci. W takiej sytuacji mówi się, że argument a jest przekazywany przez referencję.
Nasuwa się pytanie, po co przekazywać argumenty przez referencję? Ponieważ dzięki temu funkcja może modyfikować ich wartości, a więc także wpływać na dalsze działanie programu. Sprawdźmy, czy rzeczywiście tak jest. Zmodyfikuj poprzedni program zastępując w nim funkcję dodajDwa() powyższą wersją i uruchom go. Wynik jego działania będzie następujący:
Dlaczego tym razem wynik jest inny? To zarazem proste i skomplikowane.
Ponieważ zmienne a i liczba odnoszą się do tego samego miejsca w pamięci, działanie a+=2 spowodowało zmodyfikowanie zawartości zmiennej liczba. Z tego wynika, że używanie referencji może być niebezpieczne i należy ich używać tylko wtedy, gdy są naprawdę potrzebne.
Obejrzymy jeszcze jeden przypadek. Klasycznym przykładem zastosowania referencji jest funkcja zamieniająca zmienne wartościami. W naszym programie nazwiemy ją zamien():
void zamien(double& a, double& b)
{
double tymczasowa(a); // Zmienna do tymczasowego przechowania wartości zmiennej a
a = b; // Zastępujemy wartość zmiennej a wartością zmiennej b
b = tymczasowa; // Pobieramy wartość a ze zmiennej tymczasowej i zapisujemy ją w b
}
int main()
{
double a(1.2), b(4.5);
cout << "wartość a: " << a << ", wartość b: " << b << endl;
zamien(a,b); // Wywołanie funkcji
cout << "wartość a: " << a << ", wartość b: " << b << endl;
return 0;
}
Wynik działania tego kodu będzie następujący:
wartość a: 1.2, wartość b: 4.5wartość a: 4.5, wartość b: 1.2
Zmienne zostały zamienione wartościami.
Gdybyśmy nie zastosowali przekazywania argumentów przez referencję, zmienione zostałyby tylko kopie argumentów, a same argumenty pozostałyby nienaruszone. Zatem funkcja ta byłaby tak naprawdę bezużyteczna. Aby dobrze zrozumieć jak to działa, przetestuj tę funkcję z przekazywaniem argumentów zarówno przez wartość jak i przez referencję.
Przy pierwszym zetknięciu przekazywanie argumentów przez referencję może się wydawać skomplikowane i trudne do zrozumienia. Ale po pewnym czasie przekonasz się, jak bardzo przydatna jest to technika. W razie potrzeby, jeśli czegoś w pełni nie zrozumiesz, zawsze możesz wrócić do tego miejsca i przeczytać wszystko jeszcze raz. Ja też potrzebowałem trochę czasu, zanim się w tym połapałem.
7.3.3. Przekazywanie argumentów przez stałą referencję
Skoro już mowa o referencjach, pomyślałem sobie, że pokażę Ci przy okazji jakiś bardziej przydatny przykład ich użycia. To o czym tym piszę przyda nam się także w dalszej części kursu, chociaż zagadnienia te są nieco bardziej zaawansowane.
Przekazywanie argumentów przez referencję ma tę zaletę w stosunku do przekazywania przez wartość, że w jego wyniku nie następuje kopiowanie czegokolwiek. Wyobraź sobie funkcję przyjmującą argument typu string. Jeśli przekazany łańcuch będzie bardzo długi (np. cała treść tego kursu), jego skopiowanie zajmie sporo czasu mimo że wszystko odbywa się w pamięci komputera. Ta operacja kopiowania jest całkowicie zbędna i gdy ją wyeliminujemy, zwiększamy wydajność naszego programu.
W świetle przytoczonych faktów wydaje się oczywiste to, że argumenty należy przekazywać przez referencję. To prawda. Dzięki temu unikamy niepotrzebnego kopiowania. Jednak metoda ta ma jedną wadę: pozwala na modyfikowanie argumentu. Tak, właśnie po to referencje są.
void f1(string text) // Możliwe kopiowanie bardzo długiego tekstu
{
}
void f2(string& text) // Ta funkcja może modyfikować argument text
{
}
Rozwiązaniem jest zastosowanie tzw. przekazywania argumentu przez stałą referencję. Dzięki temu unikamy niepotrzebnego kopiowania a zarazem nie pozwalamy na modyfikowanie argumentu, ponieważ został zadeklarowany jako stała.
void f1(string const& text) // Brak możliwości kopiowania i modyfikacji
{
}
Nie przejmuj się, jeśli wydaje Ci się to niezbyt jasne w tej chwili. W drugiej części kursu, w której omawiane będą zagadnienia dotyczące programowania obiektowego techniki tej będziemy używać bardzo często. Wówczas w razie potrzeby wrócisz tu i odświeżysz sobie wiadomości.
7.4. Dzielenie programu na kilka plików
Na początku tego rozdziału napisałem, że funkcje tworzy się przede wszystkim po to, aby móc wygodnie używać wybranych fragmentów kodu w wielu miejscach programu. Do tej pory definicje wszystkich funkcji umieszczaliśmy przed funkcją main(), przez co ich wielokrotne wykorzystanie jest nieco utrudnione.
W języku C++ istnieje możliwość podzielenia programu na kilka plików źródłowych, z których każdy może zawierać jedną lub więcej funkcji. Dzięki temu do różnych projektów możemy dołączać tylko wybrane pliki zawierające funkcje, które są w nich akurat potrzebne. Innymi słowy pliki te są naszymi cegiełkami, z których możemy budować różne projekty.
7.4.1. Obowiązkowe pliki
Aby wydzielić funkcje do osobnego pliku, należy utworzyć dwa pliki:
- Plik źródłowy o rozszerzeniu .cpp. W tym pliku powinien znajdować się kod źródłowy funkcji.
- Plik nagłówkowy o rozszerzeniu .h. W tym pliku powinien znajdować się tylko opis funkcji zwany prototypem funkcji.
Utworzymy te dwa pliki dla naszej funkcji dodajDwa():
int dodajDwa(int otrzymanaLiczba)
{
int wartosc(otrzymanaLiczba + 2);
return wartosc;
}
Plik źródłowy
Ten plik jest prostszy z dwóch, które mamy utworzyć. Uruchom Code::Blocks i kliknij kolejno File/New/File (plik/nowy/plik), a następnie wybierz pozycję C/C++ source (plik źródłowy C/C++).
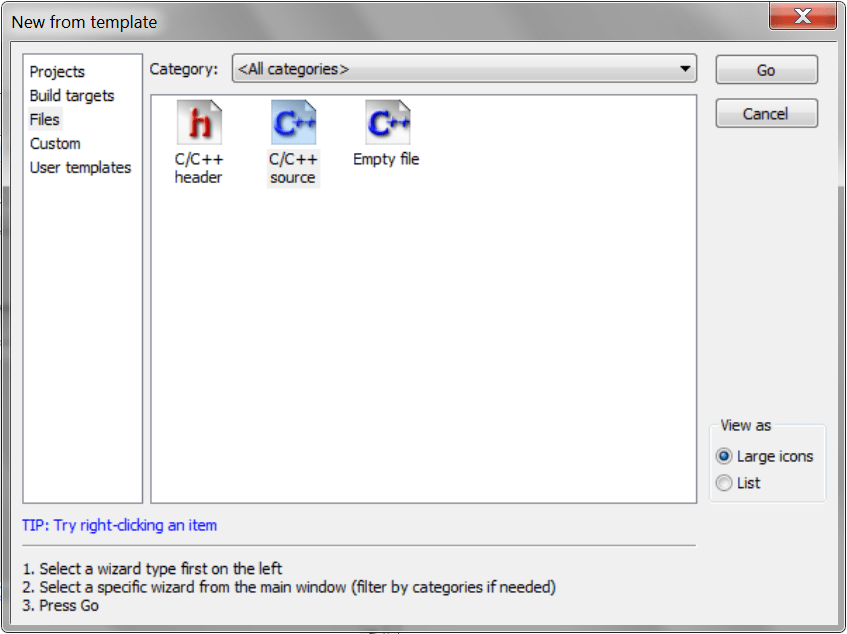
Kliknij przycisk Go. Gdy program wyświetli pytanie czy używasz języka C czy C++, wybierz C++.
Następnie zostanie wyświetlone okno, w którym trzeba wpisać nazwę tworzonego pliku. Dobrze jest wybierać nazwy, które w jakiś sposób wskazują na zawartość plików, dzięki czemu później będzie łatwiej się wśród nich zorientować. Dla funkcji dodajDwa() dobrą nazwą pliku będzie math.cpp. Plik ten zapisz w tym samym katalogu, w którym znajduje się plik main.cpp. Zaznacz też wszystkie opcje dostępne w tym oknie — rysunek 7.7.
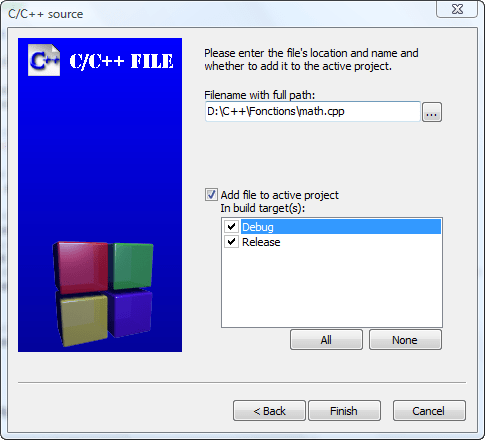
Kliknij przycisk Finish, aby sfinalizować operację tworzenia nowego pliku źródłowego. Teraz utworzymy plik nagłówkowy.
Tworzenie pliku nagłówkowego
Początkowe czynności są prawie takie same, jak w przypadku pliku źródłowego. Kliknij kolejno pozycje File/New/File i wybierz opcję C/C++ header (nagłówek C/C++) — rysunek 7.8.
W następnym oknie wpisz nazwę tworzonego pliku. Tradycyjnie nagłówkowi nadaje się taką samą nazwę, jak plikowi źródłowemu, tylko zmienia się rozszerzenie z .cpp na .h. Zatem nasz plik będzie miał nazwę math.h. Umieść ten plik w tym samym folderze, co poprzednie dwa.
Nie zmieniaj zawartości znajdującego się pod spodem pola i nie zapomnij zaznaczyć pól wyboru Debug i Release — rysunek 7.9.

Kliknij przycisk Finish, aby zakończyć.
Utworzone plik pojawią się w okienku po lewej stronie okna środowiska Code::Blocks, jak widać na rysunku 7.10.
Nazwa projektu u Ciebie może być inna niż na ilustracji.
7.4.2. Deklarowanie funkcji w pliku
Teraz możemy wpisać kod do naszych nowo utworzonych plików.
Plik źródłowy
Jak już wiemy, plik źródłowy powinien zawierać definicję funkcji. Jest to pierwsza z dwóch części (druga będzie znajdować się w pliku nagłówkowym). Kompilator musi zostać poinformowany, że pliki .cpp i .h są ze sobą w jakiś sposób powiązane i dlatego na samym początku pliku źródłowego wpisujemy poniższy wiersz kodu:
#include "math.h"
Z pewnością rozpoznajesz składnię tego wiersza. Za jego pomocą informujemy kompilator, że w programie używamy zawartości pliku o nazwie math.h.
< >.Kompletna treść pliku math.cpp jest następująca:
#include "math.h"
int dodajDwa(int otrzymanaLiczba)
{
int wartosc(otrzymanaLiczba + 2);
return wartosc;
}
Plik nagłówkowy
Gdy otworzysz utworzony przez siebie plik nagłówkowy, spostrzeżesz, że nie jest on pusty. Znajdują się w nim trzy dziwnie wyglądające wiersze kodu:
#ifndef MATH_H_INCLUDED
#define MATH_H_INCLUDED
#endif // MATH_H_INCLUDED
Kod ten uniemożliwia kompilatorowi wczytanie tego samego pliku wielokrotnie. Gdyby nie to, kompilator wykonywałby tę samą czynność w kółko. Ten kod pozwala temu zapobiec. Dlatego też nie ruszaj tych linijek, a cały swój kod wpisz między drugą a trzecią z nich.
W pliku nagłówkowym umieszcza się prototyp funkcji. Prototypem funkcji jest jej pierwszy wiesz, a dokładnie to, co znajduje się przed otwierającą klamrą. Należy skopiować tę część funkcji i na końcu postawić średnik:
#ifndef MATH_H_INCLUDED
#define MATH_H_INCLUDED
int dodajDwa(int otrzymanaLiczba);
#endif // MATH_H_INCLUDED
To wszystko. Pozostało nam już tylko jedno do zrobienia: dołączyć to wszystko do pliku main.cpp. Gdybyśmy tego nie zrobili, kompilator nie wiedziałby gdzie ma szukać funkcji dodajDwa(). Wpisz zatem poniższy wiersz kodu na początku swojego programu:
#include "math.h"
Pełny kod programu powinien wyglądać tak:
#include <iostream>
#include "math.h"
using namespace std;
int main()
{
int a(2),b(2);
cout << "Wartość a: " << a << endl;
cout << "Wartość b: " << b << endl;
b = dodajDwa(a); // Wywołanie funkcji
cout << "Wartość a: " << a << endl;
cout << "Wartość b: " << b << endl;
return 0;
}
Gotowe! Mamy prawdziwe cegiełki, z których możemy budować nasze programy. Jeśli zechcesz użyć funkcji dodajDwa() w inny projekcie, wystarczy że skopiujesz do niego pliki math.cpp i math.h.
7.4.3. Dokumentowanie kodu
Na zakończenie tego podrozdziału chciałbym jeszcze poruszyć kwestię, która może Ci się w pierwszej chwili wydać mało ważna. Już na początku kursu napisałem, że w kodzie źródłowym programu należy umieszczać komentarze, zawierające objaśnienia, dzięki którym łatwiej jest zrozumieć jego działanie.
Zasada ta jest szczególnie ważna w przypadku funkcji, ponieważ często używa się funkcji napisanych przez innych programistów. Przecież nie chcesz szczegółowo analizować kodu każdej funkcji, aby się dowiedzieć, co ona robi!
Ponieważ w pliku nagłówkowym miejsca jest pod dostatkiem, nie ma powodu, aby nie dodać do niego opisu każdej ze znajdujących się w nim funkcji. Zazwyczaj w opisie takim ujmuje się trzy informacje:
- co robi funkcja,
- lista argumentów funkcji,
- wartość zwrotna funkcji.
Bez zbędnego teoretyzowania poniżej przedstawiam przykładowy opis funkcji dodajDwa():
#ifndef MATH_H_INCLUDED
#define MATH_H_INCLUDED
/*
* Funkcja dodająca 2 do liczby przekazanej jej jako argument
* — orzymanaLiczba: liczba do której funkcja dodaje 2
* Wartość zwrotna: otrzymanaLiczba + 2
*/
int dodajDwa(int otrzymanaLiczba);
#endif // MATH_H_INCLUDED
W tym przypadku opis jest bardzo prosty, ale nie zawsze tak jest i dlatego warto wyrobić sobie nawyk rzetelnego dokumentowania swoich funkcji. Komentarze w plikach .h są tak przydatne, że istnieją nawet półautomatyczne programy, które je pobierają i tworzą z nich strony internetowe, a nawet książki.
Na przykład znany system tego typu o nazwie doxygen używa następującej notacji:
/**
* brief Funkcja dodająca 2 do liczby otrzymanej w argumencie
* param otrzymanaLiczba Liczba, do któej funkcja dodaje 2
* return otrzymanaLiczba + 2
*/
int dodajDwa(int otrzymanaLiczba);
Przydatność tego typu systemów komentarzy docenisz zapewne dopiero podczas lektury trzeciej części tego kursu, w której dostęp do dobrej dokumentacji będzie podstawą. Jeśli chodzi o wybór notacji, to nie ma znaczenia, na którą się zdecydujesz.
7.5. Domyślne wartości argumentów
Na tym etapie już doskonale wiesz czym są argumenty funkcji i jak je definiować. Poniżej przedstawiam funkcję, która do działania potrzebuje trzech argumentów. Później pokażę Ci jak ją przerobić, aby nie trzeba było ich wszystkich zawsze podawać.
int liczbaSekund(int godziny, int minuty, int sekundy)
{
int suma = 0;
suma = godziny * 60 * 60;
suma += minuty * 60;
suma += sekundy;
return suma;
}
Ta funkcja oblicza ile jest sekund w podanej liczbie godzin, minut i sekund. Krótko mówiąc nie jest skomplikowana.
Zmienne godziny, minuty i sekundy są parametrami funkcji liczbaSekund(). Są to zatem wartości, które ona otrzymuje i przy użyciu których wykonuje swoje działania.
7.5.1. Wartości domyślne
Przechodzimy do sedna sprawy. Wybranym parametrom funkcji można przypisać wartości domyślne, dzięki czemu wartości tych parametrów nie trzeba, jeśli się nie chce, podawać w wywołaniu funkcji.
Najlepiej to zrozumieć na konkretnym przykładzie. Skopiuj poniższy kod do swojego środowiska programistycznego, aby móc go wypróbować u siebie.
#include <iostream>
using namespace std;
// Prototyp funkcji
int liczbaSekund(int godziny, int minuty, int sekundy);
// Funkcja główna
int main()
{
cout << liczbaSekund(1, 10, 25) << endl;
return 0;
}
// Definicja funkcji
int liczbaSekund(int godziny, int minuty, int sekundy)
{
int suma = 0;
suma = godziny * 60 * 60;
suma += minuty * 60;
suma += sekundy;
return suma;
}
Wynik działania tego programu jest następujący: 4225
Skąd wzięła się ta liczba? Jedna godzina = 3600 sekund, 10 minut = 600 sekund, 25 sekund = 25 sekund, a więc 3600 + 600 + 25 = 4225.
Teraz wyobraź sobie, że chcesz, aby podanie niektórych argumentów wywołania tej funkcji było nieobowiązkowe, ponieważ np. najczęściej znana jest tylko liczba godzin. Aby zrealizować ten pomysł, musimy zmodyfikować prototyp naszej funkcji.
W prototypie funkcji należy przypisać parametrom wartości, jakie mają zostać im nadane w przypadku, gdy użytkownik nie określi ich w wywołaniu tej funkcji:
int liczbaSekund(int godziny, int minuty = 0, int sekundy = 0);
W tym przypadku obowiązkowe jest podanie tylko wartości argumentu godziny w wywołaniu funkcji. Dwa pozostałe argumenty są opcjonalne. Jeśli nie podamy liczby minut i sekund, zostanie im nadana domyślna wartość 0.
Poniżej znajduje się kompletny kod programu z nowym prototypem funkcji:
#include <iostream>
using namespace std;
// Prototyp funkcji z domyślnymi wartościami argumentów
int liczbaSekund(int godziny, int minuty = 0, int sekundy = 0);
// Funkcja główna
int main()
{
cout << liczbaSekund(1, 10, 25) << endl;
return 0;
}
// Definicja funkcji, BEZ wartości domyślnych
int liczbaSekund(int godziny, int minuty, int sekundy)
{
int suma = 0;
suma = godziny * 60 * 60;
suma += minuty * 60;
suma += sekundy;
return suma;
}
W powyższym kodzie w stosunku do poprzedniego zmieniliśmy tylko prototyp funkcji. Jej wywołanie pozostawiliśmy takie same, jak poprzednio, a więc wynik działania również będzie taki sam, jak poprzednim razem.
Jednak teraz, jeśli zechcemy, funkcję liczbaSekund() możemy wywoływać także z pominięciem wybranych parametrów. Możemy na przykład napisać takie wywołanie:
cout << liczbaSekund(1) << endl;
Kompilator czyta parametry od lewej, a ponieważ w tym wywołaniu podany jest tylko jeden argument i obowiązkowym argumentem jest liczba godzin, kompilator odgadnie, że podana wartość oznacza właśnie liczbę godzin. Wynik wykonania tej instrukcji będzie następujący: 3600.
Można także podać tylko liczbę godzin i minut:
cout << liczbaSekund(1, 10) << endl;
Wynik tego wywołania jest następujący: 4200.
Dopóki przekazane zostaną przynajmniej obowiązkowe parametry, wszystko będzie w porządku.
7.5.2. Przypadki szczególne i niebezpieczeństwo
Z definiowaniem domyślnych wartości parametrów wiąże się kilka pułapek. Poniżej znajduje się ich objaśnienie w formie pytań i odpowiedzi.
Czy mogę przekazać do funkcji liczbaSekund() tylko liczbę godzin i sekund, bez minut?
W tej postaci funkcja ta tego nie umożliwia. Jak napisałem wcześniej, kompilator czyta parametry od lewej strony, a więc pierwszy argument oznacza godziny, drugi — minuty, a trzeci — sekundy.
Poniższy zapis jest niepoprawny:
cout << liczbaSekund(1,,25) << endl;
Jeśli napiszesz coś takiego, kompilator szybko pokaże Ci kto tu rządzi i oznajmi że nie będzie tolerował takich zachowań. W języku C++ po prostu nie można „przeskakiwać” argumentów funkcji, nawet jeśli są one opcjonalne. Jeśli chcesz przekazać funkcji tylko pierwszy i trzeci argument, musisz także wpisać coś między nimi, np.:
cout << liczbaSekund(1,0,25) << endl;
Czy można sprawić, aby tylko liczba godzin była opcjonalna, a liczby minut i sekund obowiązkowe?
Jeśli prototyp funkcji pozostanie w takim samym stanie, jak jest teraz, to nie można tego zrobić.
Parametry opcjonalne muszą znajdować się na końcu listy parametrów (po prawej).
Poniższy kod jest zatem niepoprawny:
int liczbaSekund(int godziny = 0, int minuty, int sekundy);
// Błąd, parametry opcjonalne muszą być po prawej
Rozwiązaniem tego problemu jest przeniesienie parametru godziny na koniec listy parametrów:
int liczbaSekund(int minuty, int sekundy, int godziny = 0);
// OK
Czy można wszystkie parametry zdefiniować jako opcjonalne?
Tak, nie ma żadnych przeciwwskazań:
int liczbaSekund(int godziny = 0, int minuty = 0, int sekundy = 0);
Teraz funkcję liczbaSekund() można wywoływać w następujący sposób:
cout << liczbaSekund() << endl;
Oczywiście wynikiem tego wywołania będzie 0.
7.5.3. Zasady, które trzeba zapamiętać
Podsumowując, należy zapamiętać dwie poniższe zasady dotyczące definiowania argumentów z wartościami domyślnymi:
- Wartości domyślne należy określać w prototypie funkcji.
- Parametry z wartościami domyślnymi muszą znajdować się na końcu listy parametrów (po prawej stronie).
Podsumowanie
Programy należy dzielić na funkcje. W niektórych firmach programistycznych obowiązuje zasada, że cały kod funkcji musi się mieścić na jednym ekranie monitora! Jest to bardzo ostry wymóg, ale zmusza programistów do myślenia i dzielenia kodu na małe części.
Po lekturze tego rozdziału umiesz już posługiwać się zmiennymi, instrukcjami warunkowymi oraz funkcjami. Znasz zatem wszystkie podstawowe techniki i pojęcia. W następnym rozdziale poznasz nowy typ danych zwany tablicą.


fantastycznie wyjaśnione, w obszernych „bukwach” „uczących” programowania jest zwykle totalny mętlik, po 1000 stron (zbędnego lania wody), tu doskonale
7.3.2 zadanie
Ponizej cytuje, proszę o wyjaśnienie co robią „&” referencje w rekordzie: 1).
I jak wykonac zadanie. Czytałem ponownie ale nie mogę tego przeskoczyć…
Klasycznym przykładem zastosowania referencji jest funkcja zamieniająca zmienne wartościami. W naszym programie nazwiemy ją zamien():
void zamien(double& a, double& b)
{
double tymczasowa(a); // Zmienna do tymczasowego przechowania wartości zmiennej a
a = b; // Zastępujemy wartość zmiennej a wartością zmiennej b
b = tymczasowa; // Pobieramy wartość a ze zmiennej tymczasowej i zapisujemy ją w b
}
int main()
{
double a(1.2), b(4.5);
cout << "wartość a: " << a << ", wartość b: " << b << endl;
zamien(a,b); // Wywołanie funkcji
cout << "wartość a: " << a << ", wartość b: " << b << endl;
return 0;
}
Wynik działania tego kodu będzie następujący:
wartość a: 1.2, wartość b: 4.5 wartość a: 4.5, wartość b: 1.2
Zmienne zostały zamienione wartościami.
Ponieważ w programie tym nie zastosowaliśmy przekazywania argumentów przez referencję, zmienione zostały tylko kopie argumentów, a same argumenty pozostały nienaruszone. Zatem funkcja ta jest tak naprawdę bezużyteczna. Aby dobrze zrozumieć, jak to działa zmodyfikuj tę funkcję, aby przyjmowała argumenty przez referencję.
Dwie sprawy:
punkt 7.3.2
„Pamiętasz co to są referencje? Była o nich mowa w jednym z wcześniejszych rozdziałów.”
Niby link źródłowy w tekście jest poprawny ale nie wiedzieć czemu następuje po kliknięciu przekierowanie do kursy jQuery zamiast do punktu z referencjami c++
Sprawa druga, ważniejsza, punkty 7.5.2 i 7.5.3
cytuję kolejno:
„Jak napisałem wcześniej, kompilator czyta parametry od lewej strony, a więc pierwszy argument oznacza godziny…”
dalej:
„Parametry obowiązkowe muszą znajdować się na końcu listy parametrów (po prawej)”
dalej:
„Błąd, parametry opcjonalne muszą być po prawej”
i dalej:
„Parametry z wartościami domyślnymi muszą znajdować się na końcu listy parametrów (po prawej stronie).”
To jak to w końcu jest? Z lektury niby wynika że najpierw obowiązkowe czyli z lewej, a z prawej opcjonalne ale z powyższych wynika że wszystko ma być z prawej (: