
Do rzeczy
W tym rozdziale weźmiemy absolutnie poprawną stronę HTML i ją poprawimy. Niektóre jej części zostaną skrócone. Niektóre części się wydłużą. Ale przede wszystkim zostanie wzbogacona semantyka. Będzie świetnie.
Kod z początku strony:
<!DOCTYPE html
PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">Jest to tzw. typ dokumentu (ang. doctype). Typy dokumentu mają długą historię i wiele tajemnic. Pewnego razu programiści z Microsoftu pracujący nad Internet Explorerem 5 dla systemów Mac znaleźli się w zaskakującej sytuacji. Przeglądarka nad którą pracowali tak bardzo poprawiła się pod względem obsługi standardów, że starsze strony zaczęły w niej źle wyglądać. Tak naprawdę te strony w końcu zaczęły być poprawnie wyświetlane (zgodnie ze standardami), tylko ludzie oczekiwali, że będą się wyświetlać nieprawidłowo. Strony, o których mowa były tworzone z uwzględnieniem kaprysów najpopularniejszych w tamtych czasach przeglądarek, czyli Netscape 4 i Internet Explorer 4. A przeglądarka IE5 dla systemu Mac była tak zaawansowana, że wszystko psuła.
W związku z tym w Microsofcie wymyślono nowatorskie rozwiązanie. Przeglądarka IE5 dla systemu Mac odczytywała typ dokumentu, który powinien znajdować się w pierwszym wierszu źródła HTML strony (nawet przed elementem html). Stare strony (zbudowane wg dziwacznych zasad starych przeglądarek) zazwyczaj w ogóle nie miały określonego typu dokumentu. Przeglądarka IE 5 dla systemu Mac takie strony wyświetlała tak, jak by to zrobiły stare przeglądarki. Aby włączyć obsługę standardów, twórcy stron musieli zgłosić ten zamiar poprzez zastosowanie na stronie właściwego typu dokumentu przed elementem html.
Pomysł ten podchwyciły inne firmy i już po krótkim czasie wszystkie najważniejsze przeglądarki miały po dwa tryby działania: „dziwaczny” (ang. quirks mode) i „standardowy”. Oczywiście, jak to zwykle w sieci bywa, sytuacja szybko wymknęła się spod kontroli. Gdy Mozilla przygotowywała wersję 1.1 swojej przeglądarki, odkryto że istnieją strony prezentowane w trybie standardowym, które polegały na jednym specyficznym dziwactwie. Mozilla poprawiła algorytmy renderujące, aby pozbyć się tego dziwactwa, co spowodowało, że poprawnie przestały działać tysiące stron internetowych na raz. I wtedy — naprawdę nie zmyślam — powstał „tryb prawie standardowy”.
Henri Sivonen w swojej przełomowej pracy pt. Activating Browser Modes with Doctype (Aktywowanie trybów przeglądarek za pomocą typu dokumentu), sporządził następujące zestawienie różnych trybów:
- Tryb dziwactw
- W trybie dziwactw przeglądarki ignorują najnowsze standardy sieciowe, aby „poprawnie” wyświetlać strony, które zostały utworzone zgodnie z zasadami obowiązującymi w latach 90.
- Tryb standardowy
- W trybie standardowym przeglądarki w miarę swoich możliwości próbują przetwarzać dobrze zbudowane dokumenty zgodnie ze standardami. W HTML5 tryb ten nazywa się „trybem bez dziwactw”.
- Tryb prawie standardowy
- Firefox, Safari, Chrome, Opera (od 7.5) i IE 8 mają dodatkowo tryb zwany „trybem prawie standardowym”, w którym algorytmy określania wysokości komórek tabeli są zaimplementowane w tradycyjny sposób, niezgodny ze specyfikacją CSS 2. W HTML5 tryb ten nazywa się „trybem umiarkowanych dziwactw”.
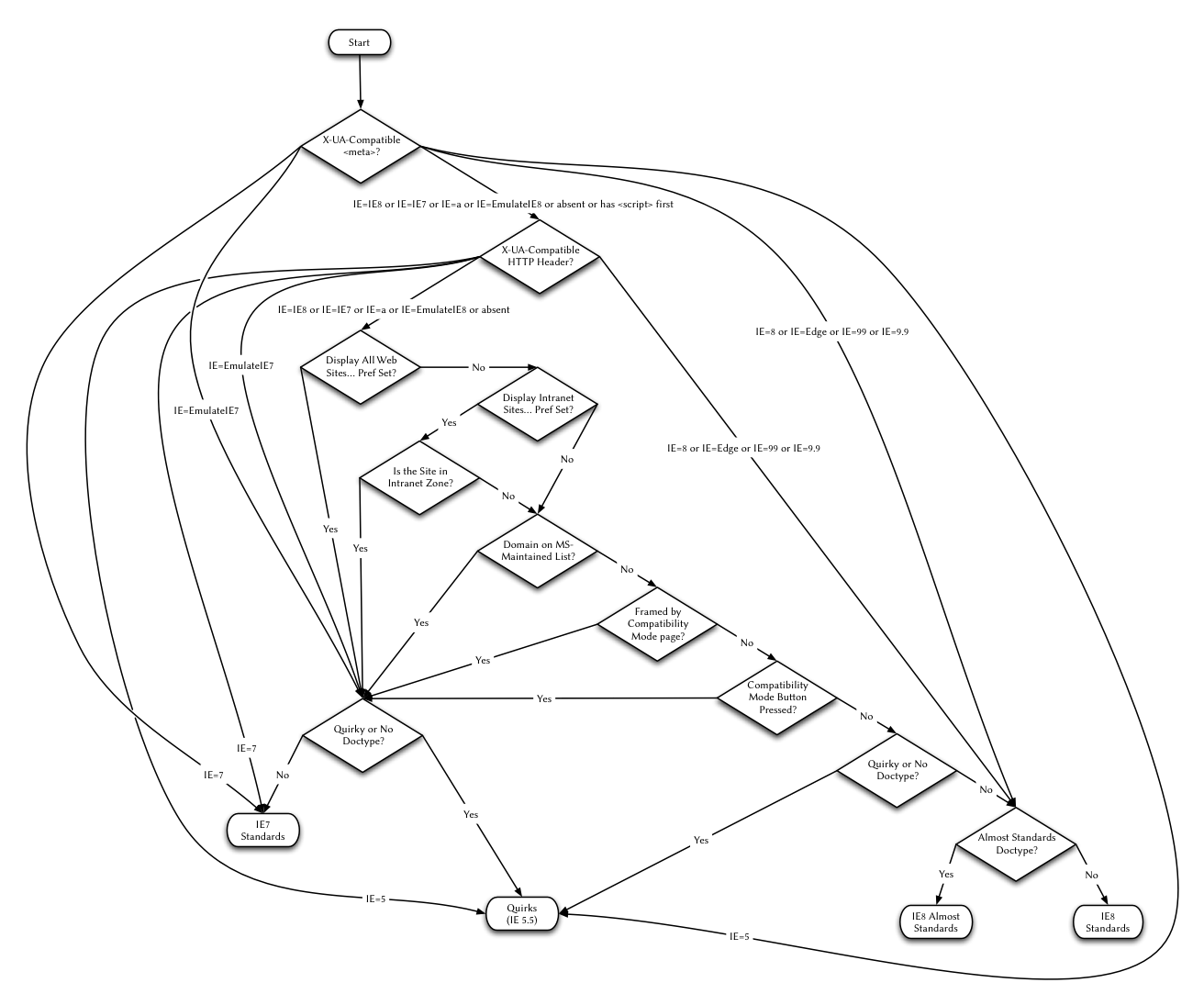
(Najlepiej przeczytaj cały artykuł Henriego, ponieważ ja tutaj bardzo dużo upraszczam. Nawet w IE 5 dla komputerów Mac było kilka starszych typów dokumentu, których nie brało się pod uwagę, jako obsługujące standardy. Z czasem lista dziwactw poszerzała się, a wraz z nią rosła liczba typów dokumentów powodujących włączenie trybu dziwactw. Ostatni raz naliczyłem pięć typów dokumentu powodujących włączenie trybu prawie standardowego i 73 włączające tryb dziwactw. Z pewnością jednak coś mi umknęło i nie mam nawet ochoty wspominać już o Internet Explorerze 8 i jego czterech — tak, czterech! — różnych trybach renderowania. Tu znajduje się ciekawy schemat. Zabić. I spalić.)
{kind=link}
Zaraz, chwileczkę. O czym to mówiliśmy? Aaa tak, typ dokumentu:
<!DOCTYPE html
PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">Przedstawiony typ dokumentu jest jednym z 15 włączających tryb standardowy we wszystkich nowoczesnych przeglądarkach. Jest absolutnie poprawny. Jeśli ci się podoba, możesz go używać. Ale możesz też zacząć używać typu dokumentu HTML5, który jest krótszy i bardziej zwięzły, a też włącza tryb standardowy we wszystkich nowoczesnych przeglądarkach.
Typ dokumentu HTML5 wygląda tak:
<!DOCTYPE html>To wszystko. Tylko 15 znaków. Jest tak prosty, że można go wpisać ręcznie i się nie pomylić.
Strona HTML to zbiór elementów umieszczonych w innych elementach. Struktura takiego dokumentu przypomina drzewo. Niektóre elementy są „rodzeństwem”, jak dwie gałęzie wyrastające z jednego pnia. Niektóre elementy mogą być „dziećmi” innych elementów, jak mniejsze gałęzie wyrastające z większych. (W drugą stronę też to działa, tzn. element bezpośrednio zawierający inny element nazywa się jego „rodzicem”, a dla „wnuków” jest „przodkiem”). Elementy (węzły) nie mające dzieci nazywają się liśćmi. Element obejmujący cały dokument, a więc będący przodkiem wszystkich pozostałych elementów na stronie nazywa się elementem głównym albo korzeniem. W dokumentach HTML elementem głównym jest html.
Na tej przykładowej stronie element główny wygląda tak:
<html xmlns="http://www.w3.org/1999/xhtml"
lang="en"
xml:lang="en">Ten kod jest absolutnie poprawny. Jeśli chcesz, możesz go używać. Jest to poprawny kod HTML5. Jednak niektóre jego części nie są już niezbędne w HTML5, a więc usuwając je możesz zaoszczędzić kilka bajtów.
Najpierw przyjrzymy się atrybutowi xmlns. Jest to pozostałość jeszcze po języku XHTML 1.0. Informuje, że elementy znajdujące się na stronie należą do przestrzeni nazw XHTML (http://www.w3.org/1999/xhtml). Ale w HTML5 elementy zawsze należą do tej przestrzeni nazw, w związku z czym nie trzeba tego dodatkowo zaznaczać. Obecność i brak obecności tego atrybutu nie mają żadnego wpływu na sposób działania strony w HTML5.
Gdy opuścimy atrybut xmlns, pozostanie nam taki element:
<html lang="pl" xml:lang="pl">Te dwa atrybuty (lang i xml:lang) określają język strony HTML. (pl oznacza polski. Nie piszesz po polsku? Znajdź i zastosuj kod swojego języka.) Po co są dwa atrybuty służące do tego samego? Jest to kolejna pozostałość po języku XHTML. W języku HTML5 działa tylko atrybut lang. Oczywiście jeśli chcesz, możesz pozostawić atrybut xml:lang, ale wówczas musisz pilnować, aby miał taką samą wartość, co atrybut lang.
Ułatwieniem dla osób przechodzących na XHTML i rezygnujących z niego jest możliwość definiowania atrybutu bez przestrzeni nazw bez przedrostka o lokalnej nazwie
xml:langdla elementów HTML w dokumentach HTML. Atrybutów takich można jednak używać tylko wtedy, gdy dodatkowo zdefiniowany jest też atrybutlangbez przestrzeni nazw i oba atrybuty muszą mieć tę samą wartość wg porównania w ASCII bez uwzględniania wielkości liter. Atrybut bez przestrzeni nazw, bez przedrostka i o nazwie lokalnejxml:langnie ma wpływu na sposób przetwarzania dokumentu.
Jesteś gotów, aby się go pozbyć? No to dalej, po prostu go usuń. Pa, pa… poszedł sobie! W ten sposób otrzymujemy taki element główny:
<html lang="pl">I to wszystko, co mam na ten temat do powiedzenia.
Pierwszym dzieckiem elementu głównego najczęściej jest element head. W elemencie head wpisuje się metadane, czyli informacje o stronie. Nie należy tu umieszczać treści właściwej dokumentu. (Treść umieszcza się w elemencie body.) Element head sam w sobie nie jest jakoś specjalnie fascynujący i w HTML5 jest taki sam, jak we wcześniejszych wersjach języka. Interesująca jest natomiast jego zawartość. Aby ją zobaczyć, jeszcze raz wrócimy do naszej przykładowej strony:
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Mój blog</title>
<link rel="stylesheet" type="text/css" href="style-original.css" />
<link rel="alternate" type="application/atom+xml"
title="Kanał wiadomości mojego bloga"
href="/feed/" />
<link rel="search" type="application/opensearchdescription+xml"
title="Wyszukiwarka mojego bloga"
href="opensearch.xml" />
<link rel="shortcut icon" href="/favicon.ico" />
</head>Omówienie tego kodu zacznę od elementu meta.
Mówiąc „tekst” najczęściej mamy na myśli znaki i cyfry, które widzimy na ekranie monitora. Jednak komputery nie porozumiewają się przy użyciu znaków i cyfr dziesiętnych, tylko przy użyciu bitów i bajtów. Każdy fragment tekstu, jaki kiedykolwiek widziałeś na ekranie monitora był zapisany przy użyciu jakiegoś rodzaju kodowania znaków. Istnieją setki metod kodowania znaków. Niektóre z nich są specjalnie dostosowane do potrzeb konkretnych języków, jak rosyjski czy chiński albo angielski, a inne obejmują wiele języków. W uproszczeniu można powiedzieć, że kodowanie znaków to odwzorowanie tego, co widać na ekranie na to, co komputer przechowuje w pamięci i na dysku.
W rzeczywistości wszystko jest trochę bardziej skomplikowane. Jeden znak może występować w kilku kodowaniach i w każdym z nich może być przechowywany w pamięci lub na dysku przy użyciu innej sekwencji bajtów. Kodowanie znaków można więc traktować jako coś w rodzaju klucza pozwalającego rozszyfrować tekst. Gdy ktoś poda nam szereg bajtów i powie, że to jest tekst, musimy znać sposób kodowania znaków w tym tekście, aby móc rozszyfrować bajty do postaci znaków i wyświetlić je (albo jakoś przetworzyć bądź zrobić z nimi jeszcze coś innego).
Skąd w takim razie przeglądarka wie, jakie kodowanie znaków zostało zastosowane w otrzymanym od serwera strumieniu bajtów? Cieszę się, że pytasz. Jeśli interesowałeś się kiedyś nagłówkami HTTP, to możliwe że widziałeś już takie coś:
Content-Type: text/html; charset="utf-8"
Jest to informacja od serwera, że został wysłany dokument HTML, w którym znaki są zakodowane przy użyciu metody UTF-8. Niestety w całym internecie tylko garstka webmasterów ma kontrolę nad używanym przez siebie serwerem HTTP. Weźmy np. takiego Bloggera: treść tworzą indywidualni użytkownicy, ale serwery należą do Google. Dlatego w HTML 4 wprowadzono możliwość określania kodowania znaków bezpośrednio w dokumencie HTML. Kod podobny do poniższego pewnie też już nie raz widziałeś:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
Wynika z niego, że zdaniem autora jest to dokument HTML zawierający znaki zakodowane przy użyciu metody UTF-8.
Obu opisanych technik można używać także w języku HTML5. Preferowaną metodą jest używanie nagłówka HTTP i jeśli jest on ustawiony, to przesłania ustawienie w elemencie meta. Ponieważ jednak nie każdy ma możliwość ustawiania nagłówków HTTP, element meta jest również wciąż dostępny. W HTML5 nawet go trochę uproszczono. Teraz wygląda tak:
<meta charset="utf-8" />
Działa to we wszystkich przeglądarkach. Skąd wzięła się ta skrócona składnia? Oto najlepsze objaśnienie, jakie udało mi się znaleźć:
Stosowanie kombinacji atrybutu
<meta charset>jest uzasadnione tym, że jest już zaimplementowana w aplikacjach klienckich, ponieważ ludzie lubią opuszczać cudzysłowy, jak tu:
<META HTTP-EQUIV="Content-Type" CONTENT="text/html;" charset="ISO-8859-2">
Istnieje nawet kilka przypadków testowych <meta charset>, które możesz obejrzeć jeśli nie wierzysz, że przeglądarki to obsługują.
Pytanie do profesora Kodeckiego
P: Ja nigdy nie używam dziwnych znaków. Czy mimo to muszę deklarować kodowanie znaków na swoich stronach?
O: Tak! Należy zawsze określać sposób kodowania znaków na wszystkich stronach HTML. Brak deklaracji kodowania może prowadzić do powstania luk w zabezpieczeniach.
Podsumujmy: kodowanie znaków jest skomplikowane a dekady używania słabego oprogramowania wykorzystywanego przez niedouczonych autorów również nie podziałało korzystnie. Należy zawsze określać kodowanie znaków w każdym dokumencie HTML albo stanie się coś złego. Można w tym celu użyć nagłówka HTTP Content-Type, deklaracji <meta http-equiv> albo krótszej deklaracji <meta charset>. Nieważne jak, ale jakoś trzeba te kodowanie określić. Internet ci za to podziękuje.
Zwykłe łącza (<a href>) służą po prostu do wskazywania innych stron. Natomiast relacje łączy służą do wyjaśniania dlaczego odsyłamy czytelnika do innej strony. Można powiedzieć, że są zakończeniem zdania „Odsyłam do tej strony, ponieważ…”
- …jest to arkusz stylów CSS, który przeglądarka powinna zastosować do tego dokumentu.
- …jest to kanał nowości zawierający taką samą treść, jak ta strona, ale w standardowym formacie przeznaczonym do subskrypcji.
- …jest to tłumaczenie tej strony na inny język.
- …jest to ta sama treść, tylko w formacie PDF.
- …jest to następny rozdział książki internetowej, której częścią jest również ta strona.
itd. W języku HTML5 wyróżnia się dwa rodzaje relacji łączy:
Przy użyciu elementu łącza można utworzyć dwie kategorie łączy. łącza do zewnętrznych zasobów to odnośniki do źródeł służących do wzbogacania bieżącego dokumentu, a hiperłącza to odnośniki do innych dokumentów. …
Sposób działania łączy do zewnętrznych zasobów zależy od relacji tych łączy.
Z przykładów, które podałem tylko pierwszy (rel="stylesheet") jest łączem do zewnętrznego zasobu. Reszta to hiperłącza do innych dokumentów. Możesz je kliknąć albo nie, ale nie są one niezbędne do oglądania strony.
Najczęściej relacje określa się w elemencie link w sekcji head strony. Są też relacje, które można definiować dla elementu a, ale rzadko kto z nich korzysta, nawet gdy jest to dozwolone. W języku HTML5 można też definiować pewne relacja dla elementu area, ale z tej możliwości korzysta jeszcze mniej osób. (W języku HTML 4 element area nie ma atrybutu rel.) Aby dowiedzieć się, do czego służą różne wartości atrybutu rel, zobacz listę wszystkich relacji łączy.
Pytanie do profesora Kodeckiego
P: Czy mogę tworzyć własne relacje łączy?
O: Wydaje się, że ludzka pomysłowość w tym zakresie jest nieograniczona. Aby zapobiec powstaniu bałaganu, społeczność skupiona wokół mikroformatów prowadzi rejestr proponowanych wartości dla atrybutu
rel, a w specyfikacji języka HTML zdefiniowano proces ich przyjmowania.
rel = stylesheet
Spójrzmy na pierwszą relację znajdującą się na naszej przykładowej stronie:
<link rel="stylesheet" href="style-original.css" type="text/css" />Jest to najczęściej używana relacja łączy na świecie. Zapis <link rel="stylesheet"> oznacza łącze do zapisanego w osobnym pliku arkusza CSS. W HTML5 jest trochę łatwiej, bo można opuścić atrybut type. Istnieje tylko jeden język arkuszy stylów do użytku na stronach internetowych (CSS), a więc atrybut type ma z góry ustaloną odpowiednią wartość domyślną. Działa to we wszystkich przeglądarkach. (Może ktoś kiedyś opracuje inny język arkuszy stylów, ale wtedy wystarczy po prostu z powrotem zacząć stosować atrybut type.)
<link rel="stylesheet" href="style-original.css" />rel = alternate
Kontynuujemy analizę naszej przykładowej strony:
<link rel="alternate"
type="application/atom+xml"
title="Kanał wiadomości mojego bloga"
href="/feed/" />Ta relacja łącza również jest bardzo często używana. Zapis <link rel="alternate"> w połączeniu z typem mediów RSS lub Atom określonym w atrybucie type włącza tzw. automatyczne wykrywanie kanału wiadomości (ang. feed autodiscovery). Dzięki niemu czytniki kanałów wiadomości (np. Google Reader) wykrywają na stronach kanały wiadomości o najnowszych artykułach. Niektóre przeglądarki w takim przypadku dodatkowo wyświetlają specjalną ikonę obok paska adresu URL. (W odróżnieniu od rel="stylesheet", tutaj atrybut type ma znaczenie. Nie opuszczaj go!)
Relacja rel="alternate" od zawsze jest dziwną hybrydą przypadków użycia, nawet w HTML 4. W HTML5 jej definicja została uproszczona i rozszerzona, aby lepiej opisywała istniejącą w internecie treść. Jak przed chwilą widziałeś, połączenie relacji rel="alternate" z atrybutem type=application/atom+xml oznacza kanał Atom dla bieżącej strony. Ale relacji rel="alternate" można używać w połączeniu z atrybutami type o innych wartościach, aby zaznaczyć tę samą treść w innych formatach, np. PDF.
W HTML5 rozwiązano także stary problem tworzenia połączeń z tłumaczeniami dokumentów. W HTML 4 do określania języka wskazywanego dokumentu należy używać atrybutu lang i relacji rel="alternate", ale to jest niepoprawne. Errata do HTML 4 zawiera listę czterech kardynalnych błędów w specyfikacji HTML 4. Jednym z nich dotyczy sposobu określania języka dokumentu wskazywanego przy użyciu elementu z atrybutem rel="alternate". Poprawnym sposobem, opisanym w erracie HTML 4 i HTML5, jest użycie atrybutu hreflang. Niestety błędów wymienionych w erracie nigdy nie poprawiono w specyfikacji HTML 4, ponieważ nikt z grupy roboczej ds. HTML W3C nie pracował już nad językiem HTML.
Inne relacje łączy dostępne w HTML5
Relacja rel="author" służy do dołączania informacji o autorze strony. Może to być adres mailto: chociaż nie musi nim być. Może to być łącze do formularza kontaktowego albo strony typu „O autorze”.
W języku HTML 4 dostępne są relacje rel="start", rel="prev" oraz rel="next" służące do określania powiązań między stronami należącymi do jednej grupy (np. rozdziały książki albo uszeregowane wpisy na blogu). Poprawnie z nich wszystkich używana była tylko relacja rel="next". Twórcy stron zamiast rel="prev" pisali rel="previous"; zamiast rel="start" pisali rel="begin" i rel="first", a zamiast rel="last" pisali rel="end".
A, i jeszcze wymyślali całkiem nowe relacje, np. rel="up" do wskazywania strony „nadrzędnej”. Relację rel="up" najłatwiej jest sobie wyobrazić patrząc na nawigację okruszkową (albo sobie ją wyobrażając). Strona główna jest pierwszym okruszkiem, a aktualnie oglądana strona — ostatnim. Relacja rel="up" wskazuje przedostatni okruszek w tej strukturze.
Język HTML5 zawiera, podobnie jak HTML 4, relacje rel="next" i rel="prev" oraz ze względu na zgodność ze starym kodem rel="previous". Kiedyś w specyfikacji były też relacje rel="first", rel="last" i rel="up". Jednak „ze względu na brak zainteresowania ze strony implementatorów i użytkowników” grupa robocza ds. HTML postanowiła je usunąć ze specyfikacji.
Drugie miejsce pod względem popularności (za rel="stylesheet") zajmuje relacja rel="icon". Najczęściej jest używana w połączeniu z relacją shortcut:
<link rel="shortcut icon" href="/favicon.ico">Wszystkie najważniejsze przeglądarki wiążą ze stroną małą ikonę, która zostanie zdefiniowana w tej relacji. Najczęściej ikona ta jest wyświetlana obok paska adresu i na kartach zakładek przeglądarki.
W języku HTML5 w połączeniu z icon można też używać atrybutu sizes służącego do określania rozmiaru wskazywanej ikony.
Relacja rel="license" została wynaleziona przez społeczność mikroformatową. „Oznacza, że wskazywany dokument zawiera informacje o prawach autorskich i licencję, na jakiej dostępny jest bieżący dokument”.
Relacja rel="nofollow" „oznacza, że dokument do którego prowadzi łącze nie jest polecany przez autora lub wydawcę bieżącej strony albo że łącze zostało wstawione na stronę w ramach działalności biznesowej właścicieli tych dwóch stron”. Relację tę wynaleziono w firmie Google i standaryzowano w mikroformatach. CMS WordPress dodaje atrybut rel="nofollow" do łączy w komentarzach do wpisów. Z relacją tą chodziło o to, że jeśli odnośniki będą nią oznaczone, to spamerzy zaniechają rozsiewania spamerskich komentarzy po blogach. Nie udało się, ale relacja rel="nofollow" pozostała.
Relacja rel="noreferrer" „oznacza, że przy przechodzeniu na daną stronę nie mają być przekazywane żadne informacje o miejscu, z którego nastąpiło przejście”. WebKit obsługuje relację rel="noreferrer", a więc działa ona w przeglądarkach Google Chrome i Safari (oraz powinna także działać w innych przeglądarkach opartych na algorytmie WebKit). [przypadek testowy rel="noreferrer"]
Relacja rel="prefetch" „oznacza, że można zawczasu pobrać do bufora podany zasób, gdyż istnieje duże prawdopodobieństwo, że użytkownik i tak zechce go pobrać”. Wyszukiwarki czasami dodają <link rel="prefetch" href="URL pierwszego wyniku wyszukiwania"> na stronach wyników wyszukiwania, jeśli dojdą do wniosku, że pierwszy wynik jest o wiele bardziej popularny niż inne. Na przykład: poszukaj w Google frazy CNN, wyświetl widok kodu źródłowego i poszukaj słowa prefetch. Przeglądarka Mozilla Firefox jak na razie jako jedyna obsługuje relację rel="prefetch".
Relacja rel="search" „oznacza, że wskazywany dokument zawiera interfejs do przeszukiwania dokumentu i powiązanych z nim zasobów”. Jeśli chcesz, aby był jakiś pożytek z użycia relacji rel="search", łącze z nią powinno wskazywać dokument OpenSearch zawierający opis sposobu, w jaki przeglądarka może skonstruować adres URL do przeszukania witryny w celu znalezienia wybranego słowa kluczowego. OpenSearch (i łącza z relacją rel="search" wskazujące dokumenty opisów OpenSearch) jest obsługiwane przez przeglądarkę Internet Explorer od wersji 7, Mozilla Firefox od wersji 2 oraz Google Chrome.
Relacja rel="tag" „wskazuje, że tag reprezentowany przez wskazywany dokument dotyczy bieżącego dokumentu”. Oznaczanie tagów (słów kluczowych używanych do kategoryzowania treści) przy użyciu atrybutu rel zostało wymyślone przez Technorati w celu ułatwienia przyporządkowywania wpisów do kategorii. Dlatego początkowo nazywano je „tagami Technorati”. (Tak, dobrze widzisz: firma nastawiona na zysk przekonała cały świat do zaadaptowania metadanych, dzięki którym praca tej firmy stała się lżejsza. Nieźle!) Później składnia tej relacji została standardowo opisana w mikroformatach, gdzie nazwano ją po prostu rel="tag". Teraz większość platform blogowych, na których można przypisywać wpisy do kategorii i tagów łącza do wpisów oznacza relacją rel="tag". Przeglądarki nie specjalnego z tym nie robią. Jest to tylko sygnał dla wyszukiwarek, aby wiedziały z czym mają do czynienia.
Język HTML5 nie powstał tylko po to, aby uprościć niektóre istniejące elementy (aczkolwiek w tym zakresie też ma spore sukcesy). W HTML5 zdefiniowano też wiele nowych elementów semantycznych.
section- Element
sectionreprezentuje ogólną sekcję dokumentu lub aplikacji. Sekcja w tym przypadku to grupa treści dotyczącej jakiegoś jednego tematu, zwykle dodatkowo opatrzona nagłówkiem. Przykładami sekcji są rozdziały w książce, strona na kartach w oknie dialogowym z zakładkami i ponumerowane części pracy naukowej. Stronę główną witryny internetowej można podzielić na sekcję wstępną, z wiadomościami i informacjami kontaktowymi. nav- Element
navreprezentuje część strony zawierającą łącza do innych stron lub miejsc na tej samej stronie: sekcja z łączami nawigacyjnymi. Nie wszystkie grupy łączy na stronie muszą znajdować się w elemencienav. Dotyczy on tylko sekcji zawierających najważniejsze bloki nawigacji. W szczególności w stopce często umieszcza się listy odnośników do różnych stron witryny, takich jak polityka prywatności, strona główna czy strona z informacjami o prawach autorskich. W takich przypadkach wystarczające jest użycie samego elementufooter, bez elementunav. article- Element
articlereprezentuje samodzielny fragment strony, dokumentu, aplikacji lub witryny internetowej, który może być rozpowszechniany w sposób niezależny od miejsca, w którym się znajduje, np. poprzez kanały RSS. Może na przykład reprezentować wpis na forum, artykuł gazety lub innego czasopisma, wpis na blogu, komentarz dodany przez użytkownika, interaktywny widżet lub gadżet itp. aside- Element
asidereprezentuje część strony, która jest bezpośrednio powiązana z treścią znajdującą się wokół tego elementu, a jednocześnie nie będąca jej integralną częścią. W druku takie sekcje najczęściej występują jako paski boczne. Elementu tego można używać do reprezentowania cytatów blokowych i pasków bocznych, reklam, grup elementównavoraz do oznaczania innych rodzajów treści, które są niezależne od treści głównej. hgroup- Element
hgroupreprezentuje nagłówek sekcji. Element ten służy do grupowania elementówh1–h6, gdy nagłówek jest wielopoziomowy, tzn. zawiera podnagłówki, alternatywne tytuły lub puentę. header- Element
headerreprezentuje treść wstępną lub podstawowe pomoce nawigacyjne. W elemencie tym zazwyczaj umieszcza się nagłówek sekcji (elementh1–h6lubhgroup), ale nie jest to konieczne. Elementuheadermożna też użyć do oznaczenia spisu treści sekcji, formularza wyszukiwania albo logo. footer- Element
footerreprezentuje stopkę swojego najbliższego przodka będącego elementem sekcyjnym. Najczęściej w stopce umieszcza się informacje o autorze treści, łącza do podobnych dokumentów, informacje o prawach autorskich itp. Stopka nie musi znajdować się na końcu sekcji, chociaż najczęściej tam właśnie się ją umieszcza. Jeśli elementfooterzawiera całe sekcje, zwykle reprezentują one dodatki, indeksy, długie kolofony, obszerne teksty licencji itp. time- Element
timereprezentuje godzinę w formacie 24 godzinnym albo konkretną datę wg rozszerzonego kalendarza Gregoriańskiego. Opcjonalnie może być określona godzina i strefa czasowa. mark- Element
marksłuży do oznaczania tekstu, na który czytelnik powinien zwrócić uwagę.
Na pewno nie możesz już się doczekać, aż zaczniesz używać tych nowych elementów, bo jeśli nie to po co czytałbyś ten rozdział. Ale chwilowo musimy odejść od głównego tematu, aby powrócić do niego za chwilę.
Każda przeglądarka ma zdefiniowaną listę obsługiwanych przez siebie elementów HTML. Przykładowo lista Firefoksa jest przechowywana w pliku nsElementTable.cpp. Jeśli jakiegoś elementu nie ma na tej liście, to uważa się go za „nieznany”. Z nieznanymi elementami są dwa problemy:
- Jak taki element ma być formatowany? Domyślnie przed i za elementem
pwstawiana jest pusta przestrzeń o określonym rozmiarze, elementblockquotejest wcięty za pomocą lewego marginesu, a elementh1ma powiększony rozmiar pisma. Ale jakie domyślne style zastosować do nieznanych elementów? - Jak powinien wyglądać DOM nieznanego elementu? Plik
nsElementTable.cppMozilli zawiera informacje o tym, jakiego rodzaju elementy może zawierać każdy element. Jeśli napiszemy kod<p><p>, to drugi akapit domyślnie stanowi zamknięcie pierwszego, dzięki czemu elementy te są w strukturze dokumentu równorzędne. Jeśli jednak napiszemy<p><span>, to elementspannie oznacza zamknięcia akapitu, ponieważ Firefox wie, że<p>jest elementem blokowym mogącym zawierać śródliniowy element<span>. Dlatego element<span>w tym przypadku będzie potomkiem elementu<p>w strukturze DOM.
Odpowiedź na postawione pytania zależy od przeglądarki. (Dziwne, prawda?) Z wszystkich najważniejszych przeglądarek najwięcej problemów w tej kwestii sprawia Internet Explorer Microsoftu, ale tak naprawdę każda przeglądarka potrzebuje trochę pomocy.
Odpowiedź na pierwsze pytanie powinna być względnie prosta: nie nadawać żadnego specjalnego formatowania nieznanym elementom. Niech normalnie dziedziczą własności CSS po elementach nadrzędnych i niech autor strony zatroszczy się o ich konkretne formatowanie. I w zasadzie tak jest, ale trzeba uważać na jedną pułapkę.
Pytanie do profesora Kodeckiego
Wszystkie przeglądarki nieznane elementy prezentują jako śródliniowe, tzn. tak, jakby miały zdefiniowane ustawienie CSS
display:inline.
Ale niektóre nowe elementy HTML5 są blokowe. To znaczy, że mogą zawierać inne elementy blokowe i przeglądarki obsługujące HTML5 domyślnie przypisują im ustawienie display:block. Jeśli chcesz ich używać w starszych przeglądarkach, musisz im tę deklarację przypisać własnoręcznie:
article,aside,details,figcaption,figure,
footer,header,hgroup,menu,nav,section {
display:block;
}(Powyższy kod został podkradziony z resetu CSS dla HTML5 Richa Clarka. Reset ten robi jeszcze kilka innych rzeczy, których opis nie należy do tematu tego rozdziału.)
Ale to nie wszystko. Jest gorzej niż myślisz! Internet Explorer do wersji 8 włącznie w ogóle nie stosuje arkuszy stylów do nieznanych elementów. Załóżmy na przykład, że mamy na stronie poniższy kod:
<style type="text/css">
article { display: block; border: 1px solid red }
</style>
...
<article>
<h1>Witaj w Initech</h1>
<p>To jest twój <span>pierwszy dzień</span>.</p>
</article>Internet Explorer do wersji 8 włącznie nie potraktuje elementu article jako blokowego ani nie zastosuje wokół niego czerwonego obramowania. Wszystkie reguły CSS odnoszące się do tego elementu w tej przeglądarce zostaną zignorowane. W Internet Explorerze 9 usterkę tę już naprawiono.
Drugi problem dotyczy struktury DOM dokumentu z uwzględnieniem nieznanych elementów. W tym przypadku również najwięcej trudności sprawiają starsze wersje Internet Explorera (starsze od wersji 9, w której już usterkę usunięto). Gdy IE 8 nie rozpoznaje elementu po nazwie, wstawia go do drzewa DOM jako pusty nie mający dzieci węzeł. Z tego powodu wszystkie elementy, które powinny być bezpośrednimi potomkami tego nieznanego elementu są z nim równorzędne.
Poniżej znajduje się atrakcyjna grafika ASCII, która doskonale ilustruje omawiany problem. Tak wygląda DOM według struktury kodu HTML5:
article | +--h1 (dziecko elementu article) | | | +--text node "Witaj w Initech" | +--p (dziecko elementu article, brat elementu h1) | +--text node "To jest twój " | +--span | | | +--text node "pierwszy dzień" | +--text node "."
A taką strukturę DOM utworzy Internet Explorer:
article (brak dzieci) h1 (brat elementu article) | +--text node "Witaj w Initech" p (brat elementu h1) | +--text node "To jest twój " | +--span | | | +--text node "pierwszy dzień" | +--text node "."
Na szczęście istnieje genialne rozwiązanie tego problemu. Przed użyciem elementu <article> na stronie wystarczy utworzyć jego atrapę za pomocą JavaScriptu, aby Internet Explorer magicznie zaczął go rozpoznawać i stosować do niego arkusze CSS. Nie trzeba nawet tej atrapy umieszczać w strukturze DOM. Wystarczy tylko raz utworzyć element na stronie, aby Internet Explorer nauczył się go rozpoznawać.
<html>
<head>
<style>
article { display: block; border: 1px solid red }
</style>
<script>document.createElement("article");</script>
</head>
<body>
<article>
<h1>Witaj w Initech</h1>
<p>To jest twój <span>pierwszy dzień</span>.</p>
</article>
</body>
</html>Sztuczka ta działa we wszystkich wersjach Internet Explorera aż do wersji 6! W ten sam sposób można włączyć obsługę wszystkich nowych elementów HTML5 na raz. Przypomnę, że nie są one wstawiane do drzewa DOM, a więc nigdy ich nie zobaczysz. Potem możesz ich używać nie martwiąc się o stare przeglądarki.
Remy Sharp napisał nawet specjalny skrypt o tajemniczej nazwie Skrypt włączający obsługę HTML5. Program ten był już wielokrotnie przerabiany, ale podstawa jego działania jest następująca:
<!--[if lt IE 9]>
<script>
var e = ("abbr,article,aside,audio,canvas,datalist,details," +
"figure,footer,header,hgroup,mark,menu,meter,nav,output," +
"progress,section,time,video").split(',');
for (var i = 0; i < e.length; i++) {
document.createElement(e[i]);
}
</script>
<![endif]-->Znaczniki <!--[if lt IE 9]> i <![endif]--> to komentarze warunkowe. Internet Explorer interpretuje je jako instrukcję if: „jeśli przeglądarka, w której otwarto tę stronę jest Internet Explorerem w wersji starszej od 9, to wykonaj ten blok kodu”. Dla wszystkich innych przeglądarek cały ten blok kodu jest zwykłym komentarzem HTML. W efekcie Internet Explorer do wersji 8 włącznie wykona skrypt, a pozostałe przeglądarki go zignorują. Dzięki temu w przeglądarkach, w których ta sztuczka jest niepotrzebna strona będzie się szybciej wczytywała.
Użyty w skrypcie kod JavaScript jest względnie prosty. Zmienna e jest tablicą łańcuchów, np. "abbr", "article", "aside" itd. Później przeglądamy ją za pomocą pętli i tworzymy elementy ze znajdujących się w niej nazw za pomocą wywołania metody document.createElement(). Jako że ignorujemy wartość zwrotną tego wywołania, elementy nie są dodawane do drzewa DOM. To jednak wystarczy, aby Internet Explorer traktował te elementy tak, jak chcemy, gdy będziemy ich używać później na stronie.
W poprzednim zdaniu bardzo ważne jest słowo „później”. Skrypt musi znajdować się na początku strony, najlepiej w elemencie head. Absolutnie nie można go umieszczać na końcu dokumentu. Dzięki temu Internet Explorer wykona go przed przeanalizowaniem elementów strony i ich atrybutów. Gdyby skrypt umieszczono na dole strony, to jego działanie byłoby spóźnione. Internet Explorer zdąży źle zinterpretować kod HTML i utworzyć nieprawidłowe drzewo DOM, a od tego nie ma odwrotu. Nie można już nic naprawić.
Remy Sharp zminimalizował swój skrypt i udostępnił go w repozytorium Google. (Dodam jeszcze, że skrypt jest otwarty i dostępny na licencji MIT, a więc można z nim robić, co się chce). Można go nawet „hotlinkować” bezpośrednio z serwerów Google:
<head>
<meta charset="utf-8" />
<title>Mój blog</title>
<!--[if lt IE 9]>
<script src="http://html5shiv.googlecode.com/svn/trunk/html5.js"></script>
<![endif]-->
</head>Teraz możesz zacząć używać nowych semantycznych elementów HTML5.
Wróćmy do naszej przykładowej strony. A konkretnie spojrzymy na znajdujące się na niej nagłówki:
<div id="header">
<h1>Mój blog</h1>
<p class="tagline">Włożono wiele wysiłku, aby robienie tego nie wymagało dużo pracy.</p>
</div>
…
<div class="entry">
<h2>Dzień wyjazdu</h2>
</div>
…
<div class="entry">
<h2>Jadę do Pragi!</h2>
</div>Ten kod jest absolutnie poprawny. Jeśli ci się podoba, możesz go używać. Jest to poprawny kod HTML5. Ale w języku HTML5 dostępne są dodatkowe semantyczne elementy do oznaczania nagłówków i sekcji.
Najpierw pozbędziemy się elementu <div id="header">. Jest to często spotykany kod, ale on przecież tak naprawdę nic nie znaczy. Element div nie ma zdefiniowanej semantyki, podobnie jak atrybut id. (Aplikacje klienckie nie mogą dedukować żadnych znaczeń z wartości atrybutu id.) Równie dobrze moglibyśmy napisać <div id="abrakadabra"> i otrzymalibyśmy to samo, jeśli chodzi o semantykę, czyli nic.
W języku HTML5 do oznaczania tego rodzaju treści służy element <header>. W specyfikacji HTML5 znajdują się realne przykłady użycia elementu <header>. Na naszej przykładowej stronie można by było go użyć w taki sposób:
<header>
<h1>Mój blog</h1>
<p class="tagline">Włożono wiele wysiłku w to, aby robienie tego nie wymagało dużo pracy.</p>
…
</header>W porządku. Każdy kogo to interesuje będzie wiedział, że jest to nagłówek. Ale co z hasłem? Jest to kolejny często spotykany przypadek, dla którego do tej pory nie było żadnego specjalnego znacznika. Znakowanie treści to trudne zajęcie. Hasło jest jak podnagłówek, tylko że „związany” z głównym nagłówkiem. Inaczej mówiąc jest to podnagłówek, który nie tworzy własnej sekcji.
Elementy takie jak h1 i h2 określają strukturę dokumentu. Razem tworzą zarys, przy użyciu którego można wizualizować stronę albo się po niej poruszać. czytniki ekranu wykorzystują zarysy do pomagania niewidomym użytkownikom w przeglądaniu stron internetowych. Istnieją nawet internetowe narzędzia i rozszerzenia przeglądarek pozwalające wyświetlić zarys dokumentu.
W HTML 4, zarys dokumentu można było tworzyć tylko przy użyciu elementów h1–h6. Zarys przykładowej strony wygląda tak:
Mój blog (h1) | +--Dzień wyjazdu (h2) | +--Jadę do Pragi! (h2)
Wszystko jest dobrze, ale nie ma jak oznaczyć hasła „Włożono wiele wysiłku w to, aby robienie tego nie wymagało dużo pracy”. Gdybyśmy użyli do tego celu elementu h2, to w zarysie dokumentu pojawił by się węzeł widmo:
Mój blog (h1) | +--Włożono wiele wysiłku w to, aby robienie tego nie wymagało dużo pracy. (h2) | +--Dzień wyjazdu (h2) | +--Jadę do Pragi! (h2)
Nie taka jest struktura dokumentu. Hasło nie reprezentuje żadnej sekcji, a jedynie podnagłówek.
Może można by było oznaczyć je elementem h2, a tytuły artykułów umieścić w elemencie h3? Nie, tak byłoby jeszcze gorzej:
Mój blog (h1)
|
+--Włożono wiele wysiłku w to, aby robienie tego nie wymagało dużo pracy. (h2)
|
+--Dzień wyjazdu (h3)
|
+--Jadę do Pragi! (h3)Nadal w zarysie dokumentu mamy węzeł widmo, ale na dodatek „ukradł” on dzieci należące do węzła głównego. Oto sedno problemu: w języku HTML 4 nie ma sposobu na oznaczenie podnagłówka bez dodawania go do zarysu dokumentu. Choćbyśmy nie wiadomo jak się starali i mieszali elementy, to zdanie „Włożono wiele wysiłku w to, aby robienie tego nie wymagało dużo pracy” zawsze znajdzie się w tym schemacie. Dlatego właśnie byliśmy zmuszeni używać bezwartościowego pod względem semantycznym elementu <p class="tagline">.
W języku HTML5 rozwiązanie tego problemu jest proste: wystarczy użyć elementu hgroup. Element hgroup jest kontenerem, w którym można umieścić dwa lub więcej powiązanych ze sobą nagłówków. Co znaczy wyrażenie „powiązane ze sobą”? Znaczy to, że elementy te razem tworzą tylko jeden węzeł w zarysie dokumentu.
Załóżmy, że mamy taki kod HTML:
<header>
<hgroup>
<h1>Mój blog</h1>
<h2>Włożono wiele wysiłku w to, aby robienie tego nie wymagało dużo pracy.</h2>
</hgroup>
…
</header>
…
<div class="entry">
<h2>Dzień wyjazdu</h2>
</div>
…
<div class="entry">
<h2>Jadę do Pragi!</h2>
</div>Ten dokument ma następujący zarys:
Mój blog (h1 ze swojej grupy hgroup) | +--Dzień wyjazdu (h2) | +--Jadę do Pragi! (h2)
Jeśli chcesz się dowiedzieć czy poprawnie stosujesz nagłówki na swoich stronach, możesz je przetestować w narzędziu do sprawdzania zarysu dokumentów HTML5.
Pozostając przy naszej przykładowej stronie, zobaczmy co da się zrobić z tym kodem HTML:
<div class="entry">
<p class="post-date">22 października 2009 r.</p>
<h2>
<a href="#"
rel="bookmark"
title="łącze do tego wpisu">
Dzień wyjazdu
</a>
</h2>
…
</div>Jest to poprawny kod HTML5. Ale w języku HTML5 dostępny są też specjalny element służący do oznaczania artykułów na stronach: element article.
<article>
<p class="post-date">22 października 2009 r.</p>
<h2>
<a href="#"
rel="bookmark"
title="łącze do tego wpisu">
Dzień wyjazdu
</a>
</h2>
…
</article>Hola, to nie takie proste. Trzeba zmienić coś jeszcze. Najpierw pokażę co, a potem wyjaśnię dlaczego:
<article>
<header>
<p class="post-date">22 października 2009 r.</p>
<h1>
<a href="#"
rel="bookmark"
title="łącze do tego wpisu">
Dzień wyjazdu
</a>
</h1>
</header>
…
</article>Wiesz o co chodzi? Zamieniłem element h2 na h1 i oba umieściłem w elemencie header. Element header już widziałeś wcześniej. Służy do grupowania elementów stanowiących nagłówek artykułu (w tym przypadku jest to data i tytuł publikacji). Ale…ale…ale… czy w dokumencie nie powinien znajdować się maksymalnie jeden element h1? Czy to nie popsuje zarysu dokumentu? Nie, ale żeby zrozumieć dlaczego, musimy nieco się cofnąć.
W HTML 4, zarys dokumentu można było tworzyć tylko przy użyciu elementów <h1>–<h6>. Jeśli chcieliśmy mieć w zarysie tylko jeden węzeł główny, musieliśmy ograniczyć się do użycia tylko jednego elementu h1. Ale w specyfikacji HTML5 zdefiniowano algorytm generowania zarysu dokumentów biorący pod uwagę nowe elementy semantyczne. W algorytmie ten element article tworzy nową sekcję, a więc nowy węzeł w zarysie. Ponadto w HTML5 każda sekcja może zawierać własny element h1.
Jest to radykalna i bardzo korzystna zmiana w stosunku do HTML 4. Wiele strony internetowych jest generowanych przy użyciu szablonów. Składa się je po kawałku z części pochodzących z różnych źródeł — trochę stąd, trochę stamtąd i otrzymujemy kompletną stronę. W ten sam sposób skonstruowanych jest wiele kursów. „Oto fragment kodu HTML. Skopiuj go i wklej na swoją stronę”. Jest to dobre rozwiązanie w przypadku niewielkich fragmentów treści, ale pomyśl co by było, gdyby trzeba było wkleić całą sekcję. W takim przypadku kurs wyglądałby mniej więcej tak: „Oto fragment kodu HTML. Skopiuj go, wklej do edytora tekstu, a następnie dostosuj nagłówki tak, aby pasowały poziomem do nagłówków, które już znajdują się na stronie, na którą masz wkleić kod”.
Innymi słowy w języku HTML 4 nie ma ogólnego elementu nagłówkowego. Są tylko ponumerowane nagłówki h1–h6, które muszą być stosowane w ściśle określonej kolejności. To poważny problem, zwłaszcza gdy strona jest „składana” z różnych części, a nie stanowi jednolitego ciągu treści. Ten właśnie problem w HTML5 rozwiązano przy użyciu nowych elementów sekcyjnych i reguł dotyczących stosowania istniejących nagłówków. Jeśli używasz nowych elementów sekcyjnych, to mogę przekazać ci poniższy kod HTML:
<article>
<header>
<h1>Wpis</h1>
</header>
<p>Lorem ipsum la la la…</p>
</article>Ty możesz ten kod skopiować i wkleić w dowolnym miejscu na swojej stronie nic w nim nie zmieniając. Zawartość elementu h1 nie stanowi tu problemu, ponieważ całość znajduje się w elemencie article. Element article w zarysie dokumentu stanowi samodzielny węzeł a element h1 jest jego tytułem. Pozostałe elementy sekcyjne na tej samej stronie pozostaną na swoim odpowiednim poziomie zagnieżdżenia.
Pytanie do profesora Kodeckiego
Oczywiście, jak to zwykle bywa z internetem, rzeczywistość jest trochę bardziej skomplikowana niż w moim opisie. Nowe „jawne” elementy sekcyjne (jak
h1warticle) mogą w dość niezwykły sposób oddziaływać ze starymi „niejawnymi” elementami sekcyjnymi (np. samodzielnie użyte nagłówkih1–h6). Będzie ci łatwiej, jeśli będziesz używać jednych albo drugich, ale nie obu rodzajów na raz. Jeśli jednak użyjesz tych dwóch rodzajów elementów na jednej stronie, sprawdź efekt w narzędziu HTML5 Outliner, aby przekonać się czy zarys twojego dokumentu jest logiczny.
Przyznasz chyba, że te wszystkie nowości są niesamowite, prawda? Może ich poznawanie nie wywołuje takiego entuzjazmu, jak zjazd nago na nartach z Mount Everest recytując Odę do młodości od końca, ale chyba nie można więcej wymagać od semantycznych znaczników HTML. Wróćmy do naszej przykładowej strony. Kolejny fragment kodu, na który chcę zwrócić twoją uwagę jest wyróżniony poniżej:
<div class="entry">
<p class="post-date">22 października 2009 r.</p>
<h2>Dzień wyjazdu</h2>
</div>Już to znamy, prawda? Typowa sytuacja: chcemy pokazać datę publikacji artykułu, a ponieważ nie ma przeznaczonego do tego celu semantycznego elementu, stosujemy ogólny element ze specjalną klasą. Jest to poprawny kod HTML5. Nie musisz go zmieniać. Ale w języku HTML5 jest dostępne lepsze rozwiązanie tej kwestii: element time.
<time datetime="2009-10-22" pubdate>22 października 2009 r.</time>Element <time> składa się z trzech części:
- znacznika czasu przeznaczonego dla komputerów,
- treści tekstowej dla ludzi,
- opcjonalnej flagi
pubdate.
W tym przykładzie atrybut datetime zawiera tylko datę, bez godziny. Format daty jest następujący: rrrr-mm-dd:
<time datetime="2009-10-22" pubdate>22 października 2009 r.</time>Jeśli chcesz dodatkowo podać godzinę, wstaw za datą literę T, a następnie wpisz godzinę w formacie 24 godzinnym, po czym podaj strefę czasową.
<time datetime="2009-10-22T13:59:47-04:00" pubdate>
22 października 2009 r. 1:59 EDT
</time>(Format daty i godziny jest bardzo elastyczny. W specyfikacji HTML5 można znaleźć przykłady poprawnie zbudowanych łańcuchów daty i godziny.)
Zwróć uwagę, że zmieniłem treść tekstową — to co znajduje się między znacznikami <time> i </time> — aby odpowiadała maszynowemu znacznikowi czasu. Nie jest to jednak konieczne. Treść tekstowa może być dowolna, ważne aby w atrybucie datetime podać poprawną datę i/lub godzinę w formacie maszynowym. W związku z tym poniższy kod jest poprawny wg zasad HTML5:
<time datetime="2009-10-22">zeszły czwartek</time>Poniższy fragment również jest poprawny:
<time datetime="2009-10-22"></time>Pozostało jeszcze wyjaśnić znaczenie cząstki pubdate. Jest to atrybut logiczny, a więc jeśli jest potrzebny, wystarczy go zdefiniować, np.:
<time datetime="2009-10-22" pubdate>22 października 2009 r.</time>Jeśli nie lubisz takich „gołych” atrybutów, to możesz też napisać tak:
<time datetime="2009-10-22" pubdate="pubdate">22 października 2009 r.</time>Co oznacza atrybut pubdate? Może oznaczać dwie rzeczy, w zależności od miejsca występowania. Jeśli element time znajduje się w elemencie article, to znaczy, że ten znacznik czasu określa datę publikacji artykułu. Jeśli element time nie znajduje się w elemencie article, to znaczy, że ten znacznik czasu określa datę publikacji całego dokumentu.
Poniżej znajduje się kompletny kod artykułu, w którym w pełni wykorzystano możliwości języka HTML5:
<article>
<header>
<time datetime="2009-10-22" pubdate>
22 października 2009 r.
</time>
<h1>
<a href="#"
rel="bookmark"
title="łącze do tego wpisu">
Dzień wyjazdu
</a>
</h1>
</header>
<p>Lorem ipsum dolor sit amet…</p>
</article>Jednym z najważniejszych składników każdej strony internetowej jest pasek nawigacyjny. W serwisie CNN.com na każdej stronie pod górną krawędzią znajdują się „zakładki” prowadzące do różnych sekcji — „Tech”, „Health”, „Sports” itd. Coś podobnego można spotkać na stronach wyników wyszukiwania Google, na których znajdują się odnośniki prowadzące do różnych rodzajów wyszukiwarek — „Obrazy”, „Wideo”, „Mapy” itd. Nasza przykładowa strona ma pasek nawigacyjny umiejscowiony w nagłówku. Zawiera on łącza do sekcji serwisu — „Strona główna”, „Blog”, „Galeria” oraz „O nas”.
Pierwotnie kod źródłowy tego paska nawigacyjnego wyglądał tak:
<div id="nav">
<ul>
<li><a href="#">Strona główna</a></li>
<li><a href="#">Blog</a></li>
<li><a href="#">Galeria</a></li>
<li><a href="#">O nas</a></li>
</ul>
</div>Jest to poprawny kod HTML5. Ale jako że został zbudowany przy użyciu listy, nie mówi nic o tym, że jest to właśnie część nawigacji serwisu. Patrząc na stronę można się tego domyślić, bo komponent znajduje się w nagłówku i zawiera łącza tekstowe. Jednak pod względem semantycznym w kodzie tym nie ma niczego, co by odróżniało tę listę odnośników od innych list.
Kogo obchodzi semantyka nawigacji witryny? Na przykład osoby niepełnosprawne. Dlaczego? Zastanów się nad taką sytuacją: masz ograniczone możliwości ruchu i z trudem, jeśli w ogóle, posługujesz się myszą. Dlatego używasz dodatku do przeglądarki, który umożliwia przechodzenie do (lub przeskakiwanie) głównych łączy nawigacyjnych. Ale pomyśl o takim przypadku: masz słaby wzrok i dlatego używasz czytnika ekranu, który czyta na głos zawartość przeglądanych przez Ciebie stron internetowych. Po tytule strony najważniejszym elementem są główne łącza nawigacyjne. Jeśli chcesz szybko dotrzeć w wybrane miejsce, poinstruujesz czytnik, aby przeszedł do paska nawigacyjnego i odczytał jego zawartość. Jeśli chcesz szybko przejść do zgłębiania treści, poinstruujesz czytnik, aby pominął pasek nawigacyjny i przeczytał treść główną strony. W obu przypadkach możliwość wyodrębnienia łączy nawigacyjnych przez program jest bardzo ważna.
Krótko mówiąc, mimo że nie ma nic złego w oznaczaniu nawigacji witryny za pomocą elementu <div id="nav">, to nie ma w tym też nic dobrego. Nie jest to optymalna metoda, jeśli wziąć pod uwagę potrzeby wszystkich użytkowników internetu. W języku HTML5 zdefiniowano specjalny semantyczny element do oznaczania sekcji nawigacji: element nav.
<nav>
<ul>
<li><a href="#">Strona główna</a></li>
<li><a href="#">Blog</a></li>
<li><a href="#">Galeria</a></li>
<li><a href="#">O nas</a></li>
</ul>
</nav>Pytanie do profesora Kodeckiego
P: Czy łączy typu pomiń można używać z elementem
nav? Czy w HTML5 takie odnośniki są jeszcze potrzebne?O: łącza takie pozwalają pominąć sekcję nawigacji. Są pomocne dla niepełnosprawnych osób, które używają programów do czytania stron internetowych na głos i nie posługują się myszą. (Dowiedz się jak i dlaczego tworzyć odnośniki pomijania nawigacji.)
Gdy czytniki ekranu zaczną rozpoznawać element
nav, odnośniki do pomijania nawigacji staną się niepotrzebne, ponieważ programy te będą mogły automatycznie przeskoczyć nawigację oznaczoną elementemnav. Jednak zanim wszyscy niepełnosprawni użytkownicy zaczną używać czytników obsługujących HTML5, upłynie jeszcze dużo wody w Cetynii. Dlatego na razie jeszcze powinno się dodawać łącze pozwalające przeskoczyć sekcjęnav.
Nareszcie dotarliśmy na sam koniec naszej przykładowej strony. Na zakończenie kilka słów o ostatnim elemencie strony, czyli stopce. Początkowo stopkę oznaczyliśmy następująco:
<div id="footer">
<p>§</p>
<p>© 2001–9 <a href="#">Mark Pilgrim</a></p>
</div>Jest to poprawny kod HTML5. Jeśli ci się podoba, możesz go używać. Ale w języku HTML5 jest dostępny lepszy element służący do oznaczania stopki: element footer.
<footer>
<p>§</p>
<p>© 2001–9 <a href="#">Mark Pilgrim</a></p>
</footer>Co powinno się umieszczać w elemencie footer? Najprościej mówiąc, wszystko to, co umieściłbyś w elemencie <div id="footer">. Wiem, to pokrętna odpowiedź. Ale naprawdę jest bardzo dobra. Według specyfikacji HTML5: “Najczęściej w stopce umieszcza się informacje o autorze treści, łącza do podobnych dokumentów, informacje o prawach autorskich itp.” Informacje takie znajduje się w stopce także naszej przykładowej strony: krótka informacja o prawach autorskich i odnośnik do strony o autorze. Kiedy jednak przeglądam różne strony internetowe, to dostrzegam w stopce bardzo duży potencjał.
- W portalu CNN stopka zawiera informację o prawach autorskich, łącza do tłumaczeń oraz odnośniki do warunków korzystania, polityki prywatności, strony z informacjami o firmie, strony z danymi kontaktowymi i stron pomocy. Wszystko to doskonale nadaje się do umieszczenia w elemencie
footer. - Google słynie ze swojej wyjątkowo ascetycznej strony głównej, ale na dole znajdują się łącza „Reklamuj się w Google”, „Rozwiązania dla firm”, „Prywatność i warunki”, „Wszystko o Google” oraz informacja o prawach autorskich. To również jest dobrym materiałem do umieszczenia w elemencie
footer. - Mój blog ma stopkę zawierającą łącza do moich innych stron i informacje o prawach autorskich. Nie ma wątpliwości, że taką treść można umieścić w stopce. (Zwróć uwagę, że odnośników w tym przypadku nie należy umieszczać w elemencie
<nav>, ponieważ nie należą do głównej nawigacji witryny. Są to po prostu odnośniki do innych moich prac.)
“Ostatnio wielką karierę robią tzw. wypasione stopki (ang. fat footer). Spójrz np. na stopkę w serwisie W3C. Zawiera trzy kolumny zatytułowane „Navigation”, „Contact W3C” oraz „W3C Updates”. Kod źródłowy wygląda mniej więcej tak:
<div id="w3c_footer">
<div class="w3c_footer-nav">
<h3>Navigation</h3>
<ul>
<li><a href="/">Home</a></li>
<li><a href="/standards/">Standards</a></li>
<li><a href="/participate/">Participate</a></li>
<li><a href="/Consortium/membership">Membership</a></li>
<li><a href="/Consortium/">About W3C</a></li>
</ul>
</div>
<div class="w3c_footer-nav">
<h3>Contact W3C</h3>
<ul>
<li><a href="/Consortium/contact">Contact</a></li>
<li><a href="/Help/">Help and FAQ</a></li>
<li><a href="/Consortium/sup">Donate</a></li>
<li><a href="/Consortium/siteindex">Site Map</a></li>
</ul>
</div>
<div class="w3c_footer-nav">
<h3>W3C Updates</h3>
<ul>
<li><a href="http://twitter.com/W3C">Twitter</a></li>
<li><a href="http://identi.ca/w3c">Identi.ca</a></li>
</ul>
</div>
<p class="copyright">Copyright © 2009 W3C</p>
</div>Gdybym chciał użyć nowych semantycznych elementów HTML5, dokonałbym następujących modyfikacji:
- Zewnętrzny element
<div id="w3c_footer">zamieniłbym na element<footer>. - Dwa pierwsze elementy
<div class="w3c_footer-nav">zamieniłbym na elementy<nav>, a trzeci — na<section>. - Nagłówki
<h3>zamieniłbym na<h1>, ponieważ teraz każdy z nich będzie znajdował się w elemencie sekcyjnym. Element<nav>, podobnie jak<article>, tworzy sekcję w zarysie dokumentu.
W efekcie kod źródłowy tej stopki wyglądałby tak:
<footer>
<nav>
<h1>Navigation</h1>
<ul>
<li><a href="/">Home</a></li>
<li><a href="/standards/">Standards</a></li>
<li><a href="/participate/">Participate</a></li>
<li><a href="/Consortium/membership">Membership</a></li>
<li><a href="/Consortium/">About W3C</a></li>
</ul>
</nav>
<nav>
<h1>Contact W3C</h1>
<ul>
<li><a href="/Consortium/contact">Contact</a></li>
<li><a href="/Help/">Help and FAQ</a></li>
<li><a href="/Consortium/sup">Donate</a></li>
<li><a href="/Consortium/siteindex">Site Map</a></li>
</ul>
</nav>
<section>
<h1>W3C Updates</h1>
<ul>
<li><a href="http://twitter.com/W3C">Twitter</a></li>
<li><a href="http://identi.ca/w3c">Identi.ca</a></li>
</ul>
</section>
<p class="copyright">Copyright © 2009 W3C</p>
</footer>Lektura uzupełniająca
Przykładowe strony omawiane w tym rozdziale:
O kodowaniu znaków:
- Absolutne minimum, jakie bezwzględnie każdy webmaster powinien wiedzieć o Unicode i zestawach znaków (bez wymówek!), Joel Spolsky (tekst po angielsku)
- O pożytkach płynących z Unicode, O łańcuchach znaków oraz Znaki a bajty, Tim Bray (teksty po angielsku)
O włączaniu obsługi nowych elementów HTML5 w Internet Explorerze:
- Jak formatować za pomocą CSS nieznane elementy w IE, Sjoerd Visscher (tekst po angielsku)
- HTML5 shiv, John Resig (tekst po angielsku)
- Skrypt włączający obsługę HTML5, Remy Sharp (tekst po angielsku)
- Historia HTML5 Shiv, Paul Irish (tekst po angielsku)
O trybach obsługi standardów i wykrywaniu typu dokumentu:
- Włączanie trybów działania przeglądarek przy użyciu typu dokumentu, Henri Sivonen. To jedyny artykuł na ten temat, jaki należy przeczytać. Każda inna publikacja o typach dokumentów, w której nie ma odniesienia do pracy Sivonena na pewno jest przestarzała, niekompletna albo zawiera błędy (tekst po angielsku)
Walidator obsługujący HTML5: